 | Rank Ranger")
Posted by
Darrell Mordecai
We all feel it.
SEO has changed dramatically.
What used to work when I started out (when the world was still in black and white), is not working like it used to.
And, as the search engines evolve we SEOs have to evolve with it.
When trying to find answers, I discovered semantic SEO. Although early applications of semantic search actually **** back to 2009, it’s picked up steam over the years eventually creating a revolution in how search engines work.
I discovered that semantic search influences all of the SEO basics, including:
- Keyword research
- Search intent
- Content creation
- Site architecture
- Internal linking
- And more
In this blog post, I’ll be giving you an overview of semantic search. My goal is to give you a solid foundation to work with so that when you learn semantic SEO strategies you’ll understand why they work.
In order to make this post as useful as possible, I’ve attempted to keep the language simple and I’ve avoided making the post overly long. I do intend to create follow-up content that will get into the specific strategies.
Semantic Search
So everything starts with semantic search.
But, what is semantic search?
Semantic search describes how Google aims not merely to bring results by matching keywords to the search query but now Google determines the intent and meaning of the query in order to bring complete results designed to:
- Answer exactly what the user is searching for
- Bring results that predict the user’s next question before they even ask it
So, how exactly does Google do that?
Well, to achieve this, Google and other search engines over the years have changed the way they categorize information.
In the old days, Google would match a search query to a web page by using on-page and off-page factors. This meant matching the query to keywords that appeared in prominent places in your content. You know, title tags, H1s, anchor text, alt tags, and all those basic SEO optimizations you learned about.
It’s important to note that to Google, the search query and the content were in those days no more than strings of characters which resulted in keyword-focused SEO strategies.
This means Google identified and classified the content by examining the title tags etc. Once Google classified the content this way, Google was able to bring search results by matching the content to keywords found in the search query.
But in 2012, Google introduced Hummingbird which was a revolution in how search engines categorize information. In other words, Google made a push away from strings and replaced them with things.
This means Google is now storing information about real-world entities (or things) in a database called a Knowledge Graph. Google also has information on how these entities relate to one another and this paradigm shift in categorizing information has dramatically shaped the results pages.
This means a search query is no longer a mere string of characters. Google can now ‘understand’ that the string is referring to a specific entity.
Now that you have a basic overview, I need to explain:
- What the Google Knowledge Graph is
- What Google entities are
- How Google understands the relationships between entities
What is Google’s Knowledge Graph?
Google’s Knowledge Graph is a database of facts about entities (people, places, and things). This database allows Google to answer questions about each entity and display these answers and related facts in the search results.
Google compiles these facts from a number of different sources including:
- Public sources such as Wikipedia and the CIA World Factbook
- Licensed information such as sports scores and weather forecasts
- Content owners
However, having massive amounts of information isn’t useful unless it’s categorized and structured. (I’ll explain how Google structures this information later in this post.)
This allows Google to feature two types of information about a given entity in the search results.
Firstly Google will give a general summary of the general topic. This might be a definition or a brief summary of a famous person’s life.
Secondly, by understanding the relationship between things, Google is able to present related information and related queries on the topic. This allows the user to explore the topic on their own.
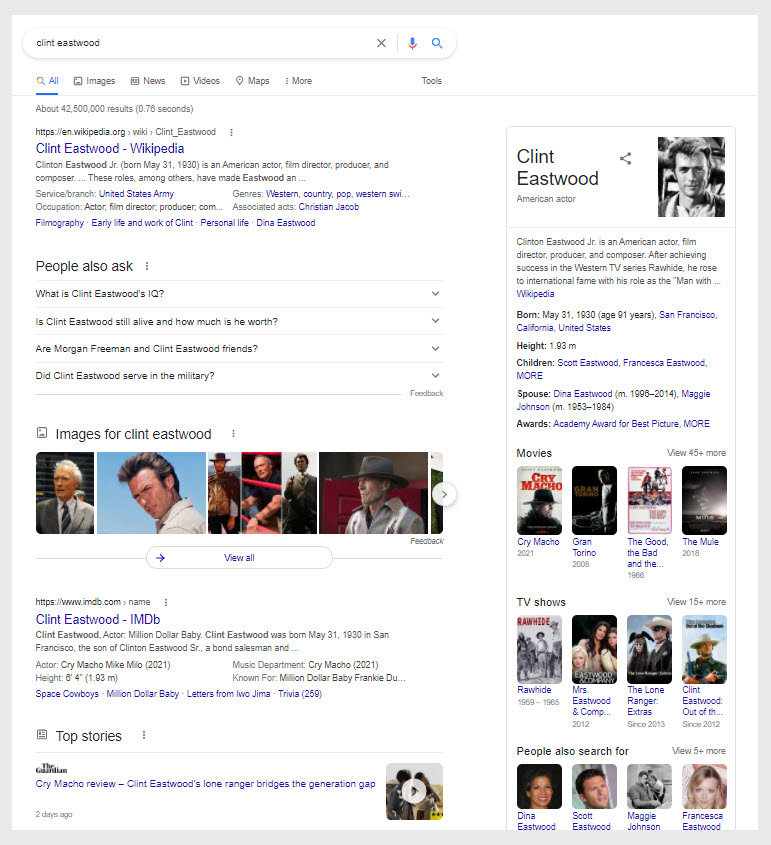
For instance, if you look at the screenshot above, you’ll see a Knowledge Panel on the right-hand side of the screen. The top of the Knowledge Panel defines who Clint Eastwood is while giving basic information.
If you’ve understood the basic information and are a bit curious to explore the topic further, the Knowledge Panel features a list of movies, the People Also Ask box features commonly asked questions and the Top Stories feature presents current news stories.
By adding all of these options, Google is prompting the user to explore more information about the entity.
Okay, so we’ve explored the Knowledge Graph a bit, let’s now understand what entities are.
What are Google Entities?
Google defines entities as ‘A thing or concept that is singular, unique, well-defined and distinguishable.’
Although we might imagine an entity refers to an object, by Google’s definition, an entity could just as well refer to something abstract like a concept. But, to be defined as an entity they are represented linguistically by nouns. Put another way, an entity is a thing that can be identified, classified, and categorized.
This means even colors, feelings or ideas can be entities.
Now, in order to truly ‘understand’ these entities, Google has to give them context by assigning them attributes.
For instance, a query for ‘apple’ is ambiguous to Google. Which entity is the searcher looking for information about? Are they searching for results about the fruit or Apple the company?
By categorizing one entity as a type of fruit and another as a brand that sells devices, Google is able to categorize apples in two different ways and therefore serve two completely different search intents with two different entities.
Google’s Knowledge Graph doesn’t just assign attributes to entities to define them as unique. Google also uses these attributes to ‘understand’ how these entities are interconnected. Entities with similar attributes are grouped together.
In other words, apples, oranges, and pears are all grouped as fruit.
On top of that, Google’s Knowledge Graph also groups entities into topics and is able to understand that topics exist in a hierarchical structure of topics and sub-topics.
Google calls this the Topic Layer.
The topic layer allows Google to dynamically add sub-topic tabs to its Knowledge Panels transforming the search experience from a single search into a journey that can potentially take a searcher through an entire topic.
So for instance, if you were to search the broad topic ‘the universe’ you might be looking for general information. But, once you get what you came for, you might want to explore the topic further.
Google helps you out by adding sub-topics to the Knowledge Panel.
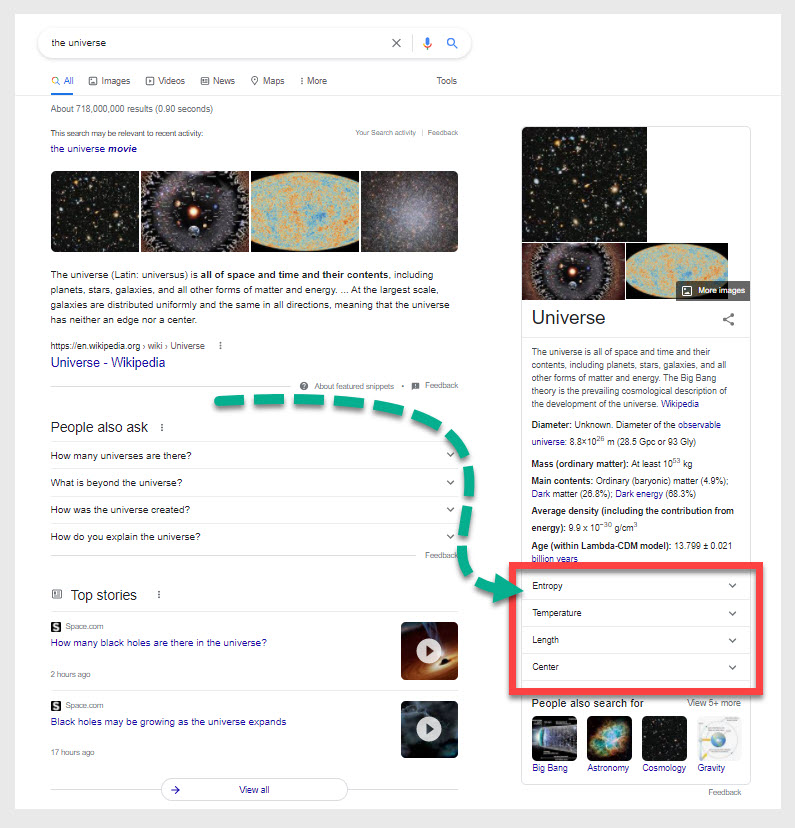
As you can see in the screenshot above, Google adds expandable dropdown tabs for the sub-topics:
- Entropy
- Temperature
- Length
- Center
This shows us that Google is able to not only group entities through shared attributes but also understands how they exist in a hierarchy of topics and sub-topics.
If you want to understand this further, check out our entity analysis of Google’s Topic Layer.
Once we understand what entities are, let’s take a deeper look at how search engines understand their relationships. What is the anatomy of information in Google’s Knowledge Graph?
Well, this all leads us to triples.
What is a Triple?
A triple refers to the relationship between two entities. These relationships exist as information in the Knowledge Graph that is structured using a subject-predicate-object structure.
Simply put, the subject and object are entities. The predicate describes the relationship between these two entities.
So for example, if we were to look at the sentence ‘Darrell likes music.’
The sentence is made up of:
- A subject: Darrell
- Predicate: Likes
- Object: Music
Both the subject and object in this example are entities. The word ‘likes’ would describe the relationship between the entities.

Taking this further, the object in our triple ‘music’ could be the subject in a different triple.
So the sentence ‘Music is an art form’ uses the entity ‘music’ that appeared as the object in the last sentence ‘Darrell likes music’. However, that entity is now a subject in this new sentence.
By interlinking entities in this way, Google has linked three entities together. By storing information in this way, Google links literally millions of entities to one another.
By understanding this concept you have one of the foundations of semantic SEO.
What Happens When Someone Searches Google?
So we have covered some basic concepts in understanding semantic search. Now let’s put everything together by looking at what actually happens when someone searches Google.
To understand this, we have to basically understand how Google treats search queries, as that’s the first step in Google bringing results to the results pages.
Understanding Search Queries
For a search engine to bring complete results that closely match the user’s intent and take the user on a journey of discovery, Google needs to understand what the user is searching for when they type a query into their browser.
To achieve this Google’s natural language processing algorithms attempt to understand the underlying meaning of the searcher’s query.
This is not so easy to achieve, however. As people, we tend to find many ways to say the same thing, and wording a question in different ways can often create slightly different meanings.
What’s more, it’s important to understand that Google is not able to understand language the way a human can. In other words, Google can’t (yet) understand user intent from sentence structure and linguistics.
But, Google is able to look at its database of entities and their relationships and basically figure out what a searcher is searching for.
For instance, type these two different searches into Google:
- who are the members of the red *** chili peppers
- red *** chili peppers members

If you did you’ll notice that both queries brought similar results even if one query was worded as a question while the other was only an implied question. The reason is Google is able to understand the entity ‘Red *** Chilli Peppers’. Google also understands that this entity has other entities associated with it.
The entity Anthony Kiedis for instance is closely related to the entity Red *** Chilli Peppers.
What’s more, that relationship is defined as a ‘member’.
Having this relationship in its database, Google treats the two queries the same way even if one query includes the words ‘who are’ while the other merely names the entity Red *** Chilli Peppers and attaches the word members.
The user is looking for these closely related entities defined as ‘members’. Google can then bring results based on its ‘understanding’ of the query.
Now, what happens when Google doesn’t ‘understand’ the query? What happens if Google’s database doesn’t include the entities the query is about, or the database doesn’t understand the connection between entities?
In cases like this, Google relies on algorithms like Rank Brain to imitate semantic understanding.
Rank Brain does this by using a database of similar queries and basically makes a guess.
This can sometimes result in multiple search intents on a SERP.
=> Check out our guide on how to perform a SERP analysis to understand user intent.
Why Semantic Search?
As a side point, this all begs the question, why?
I mean it looks like Google has invented the world’s most sophisticated library.
The answer is, by understanding entities and their relationships, Google is able to provide a stellar user experience. Based on Google’s data it’s able to present a topic from the top down. This means when a searcher searches a topic, Google is able to provide information the searcher was looking for as well as predict what the searcher wants to know next.
To do this, Google will present closely related user intents into any given SERP. This way, once the user has what they are looking for, new questions might arise in their minds. In other words, the original question turns into a journey of discovery, resulting in many searches.
If you want to see this in action, check out our blog post: Understanding User Intent (Analyzing Multiple user intents)
Semantic Search in a Nut Shell
Hopefully, now that you’ve seen this post, you’re in a good position to delve into some actionable semantic SEO strategies. Although I have attempted to keep the language simple to truly understand the topic it’s a good idea to keep reading. In other words, treat this blog post as a springboard to build your knowledge further.
Luckily there is a wealth of information online that you can sink your teeth into, such as content created by people like Bill Slawski, Koray Tuğberk GÜBÜR, and Jason Barnard who break down different aspects of semantic SEO.
Now that you understand semantic search, I’m sure you’re wondering how you can use it to boost your rankings and traffic. The first step is understanding the difference between keywords and topics.
About The Author




