
Posted by
Darrell Mordecai
There is no question that semantic SEO is the future of SEO.
The reason?
As search engines evolve towards semantic search your SEO strategy should evolve with them.
The problem is the barrier to entry is high. In other words, to do semantic SEO you must have a basic understanding of how semantic search works.
Unfortunately, as things stand at the moment, if you do a Google search for simple easy-to-understand resources for the layman you’ll find yourself scratching your head.
To deal with that, I’ve attempted to create some semantic SEO resources that anyone can understand.
This blog post and all the others in this series represent my own quest to understand semantic SEO. I have to acknowledge that this post comes mostly from information gleaned from Krisztian Balog’s ebook Entity Oriented Search.
In this post I’ll be dealing with the question:
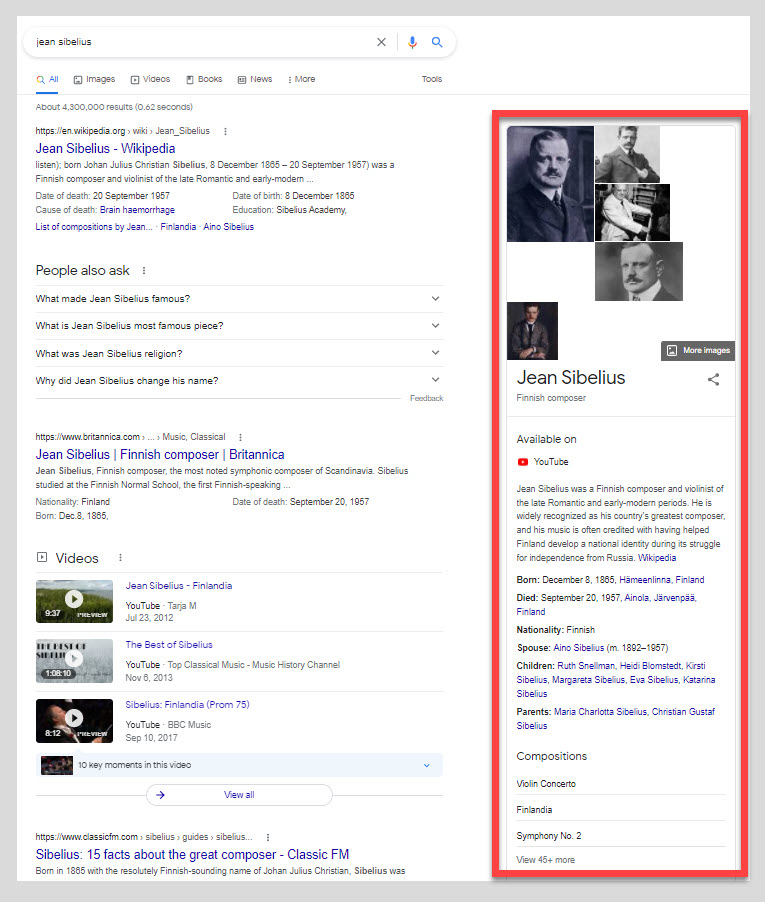
What is Google’s Knowledge Graph?
At a 30,000 ft level, Google’s Knowledge Graph is a Knowledge Base of entities that are structured into a graph called a Knowledge Graph.
In case you have no idea what that statement means, have no fear, I’ll attempt to pick it apart and explain each segment one by one. I’ll then attempt to piece it all back together into a coherent sentence that’ll be understandable to the layman.
I certainly consider myself a layman and that means I hope to use language that’s simple to understand.
It’s interesting to note that Google’s Knowledge Graph directly interacts with the SERPs. The most obvious place to see this is Google’s Knowledge Panels. Knowledge Panels are a way for the end user to interact with the entity information in the Knowledge Graph.
To get started in understanding Google’s Knowledge Graphs, we first need to understand why search engines are evolving toward semantic search.
Semantic Search
Simply put, a semantic search engine is designed to interact with people using language that a person would use.
Why do search engines do that?
Well, if you’ve been around for a while you might remember what typing a query into a search engine was like fifteen or twenty years ago. If you recall it was highly inaccurate. You’d try to figure out the right words to type into the search engine and you’d then have to dig around to find the resource you were looking for.
The reason for this is search engines at that time had no way of understanding your query. Nor could they fathom what the meaning of online content was in order to answer your query.
Contrast that with your experience using search engines today. Have you ever noticed that Google can almost intuitively bring you content that’s not only relevant to your query but can often directly answer your query in the results pages?
So, how does Google do that?
Natural language processing (NLP).
Google’s Natural language processing is its ability to ‘understand’ and interact with natural human language.
And…
In order to achieve natural language processing, they need machine-readable databases of information structured in a way that imitates how humans organize information.
By having the information structured in this way, search engines are able to ‘understand’ a user’s query and bring relevant resources to answer the query by ‘understanding’ online content.
Although machines don’t actually understand language, they are able to imitate understanding.
Now in order to organize information in a way that allows machines to do this, they need to break ideas and information up into entities.
Okay, so what are entities?
What is a Google Entity?
A Google entity is defined by Google as “A thing or concept that is singular, unique, well-defined, and distinguishable.”
Simply put search engines have databases of entities and these databases include entity information like name, type, attributes, and how entities relate to other entities.
As I mentioned above, the reason search engines keep databases of entities is so that they can organize information into a structure that imitates the way people structure information.
Entities are the smallest building blocks needed to organize information in this way.
Okay, now we have a basic understanding of entities, let’s move on to knowledge graphs.
Understanding Google’s Knowledge Graph
Google’s Knowledge Graph is made up of different component parts. The reason for this is for search engines to answer user’s queries, they need to:
- Have a reliable source of information
- Structure that information in a way that will allow the search engine to answer queries
This brings us to:
- Knowledge repositories (KR)
- Knowledge bases (KB) often referred to as knowledge graphs (KG)
Let’s delve into both.
Knowledge Repository (KR)
Knowledge repositories are sources of information that search engines use to build knowledge bases. They are catalogs of entities that arrange the entities into entity types.
They can optionally include descriptions of the entities as well as entity properties. These knowledge repositories exist in structured or semi-structured formats.
The perfect example of a knowledge repository is Wikipedia. Each Wikipedia article describes a specific entity, making it an entity catalog.
What’s more, each article is assigned to categories and we can view these categories as entity types.

So in the screenshot above, you can see the categories for the entity ‘natural language processing’. As you can see natural language processing is a category of entities. What’s more, it’s a subcategory of computational linguistics. Computational linguistics is a subcategory of speech recognition etc.
Wikipedia articles also show relationships between entities by adding hyperlinks between articles. They also include information about an entity’s attributes and relationships.
All of this information is in a semi-structured format.
Semi-Structured Knowledge Repositories
Semi-structured data simply refers to information that has some structure such as HTML markup including headings, paragraphs, and tables.
Simply speaking Wikipedia is a semi-structured Knowledge Repository.
Structured Knowledge Repositories
Structured data (or relational databases) on the other hand, simply refer to data that has a predetermined structure or schema. Structured data is typically organized into tables. This means every field specified by the schema must be given a (permitted) value.
Once search engines have this structured or semi-structured information, it’s still not ordered in a way that search engines can use it for semantic search.
The next step is knowledge bases (or knowledge graphs).
Knowledge Bases or Knowledge Graphs
It’s important to understand that for AI software to perform complex NLP tasks, such as understanding user queries, they need data to be structured in a specific way.
In other words, structured data in table form or semi-structured data like Wikipedia blog posts do not give the AI systems what they need to process human language.
Instead, the information needs to be structured in a similar way to how people organize information in their minds.
To do this, Knowledge Bases have to take information from Knowledge Repositories and organize it into assertions about the world. These assertions describe entities and how they relate to one another. I’ll describe this more in detail later.
To do this, search engines need a data model called the Resource Description Framework (RDF). RDF provides a standard set of statements describing entities or resources.
Resource Description Format (RDF)
RDF is a language designed to describe entities and their relationships. It’s made up of resources.
A resource could refer to:
- An entity or object
- An entity type or class
- Entity relationships
These resources are arranged into RDF statements called semantic triples.
Semantic triples are a set of three entities arranged into a statement in the form of subject-predicate-object. (Represented in graph form an RDF statement is represented by a node for the subject, an edge going from subject to object, and a node for the object.)
The subject and predicate are represented by their own numeric identifier called a URI. The object of the statement can either be represented by a URI or could be a literal value.
For those of you who are visual learners, here is an illustration:

The subject of a triple is an entity. The predicate could be an entity type or relationship. For instance, nationality, **** of birth, name, etc. The object is either another entity or a value such as a string representing a name, or a number representing a ****.
So, for example, let’s look at the first sentence in the Wikipedia article about Mike Tyson:
Michael Gerard Tyson (born June 30, 1966) is an American former professional boxer who competed from 1985 to 2005.
Let’s break that down visually.

In the illustration above, I’ve represented the first phrase as a triple.
The subject is the entity ‘Mike Tyson’, the predicate is ‘birth ****’ and ‘1966-06-30’ is the object. I’ve put a rectangle around Mike Tyson to represent that Mike Tyson is an entity. 1966-06-30 on the other hand is not an entity but rather a value so I’ve included it in inverted commas.
Here is a visual representation of the entire sentence:
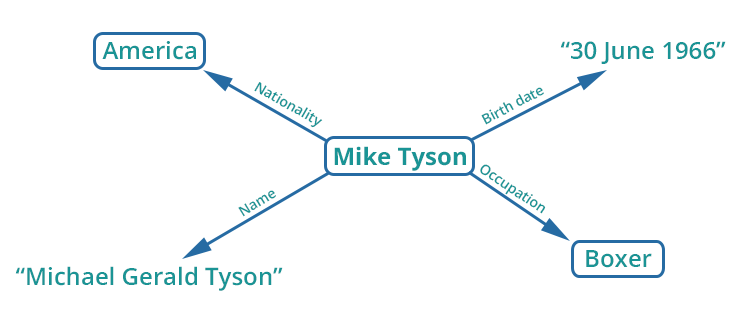
Taking this further, any entity that exists in the example above can be seen as the subject in a different set of triples, resulting in a large intricate network of entities and relationships.
The (Far From) Final Word About Knowledge Graphs
You should now have a basic understanding of what a knowledge graph is. What’s more, you should have a layman’s understanding of the information stored in knowledge graphs and you should also understand where it comes from.
Although there are no actionable strategies in this post, I do feel this knowledge is a basic foundation in understanding semantic SEO that will help you further down the path to SEO stardom.
And understanding leads to actionable insights.
About The Author




