

Twiddlers are C++ code objects used in Google’s ranking algorithms that help Google re-order search results. They are used in a Google system called Superroot which is Google’s ranking framework.
I came across this 2017 Google document on Twiddlers upon reading Mario Fischer’s excellent breakdown of what we can learn about how ranking works based on the DOJ vs Google trial and also the recently discovered API files containing many attributes potentially used in ranking.
Here is the Google document. We need to keep in mind it was written in 2018, so likely there are quite a few new Twiddlers in use now, but there is still a lot we can learn:
Twiddler Quick Start Guide – Internal Google documentation
What do Twiddlers do?
Twiddlers are essentially algorithms that can be used to adjust the order of Google’s search results after initial ranking is done. They make recommendations (called twiddles) on how to re-rank web pages based on various signals.
As of 2018, there were hundreds of twiddlers, each trying to optimize for certain signals. Given that search technology has advanced since then, there are likely quite a few more twiddlers that Google uses today.
Twiddlers can be used to boost certain results, filter results to increase diversity, remove duplicates and remove spam, and more.
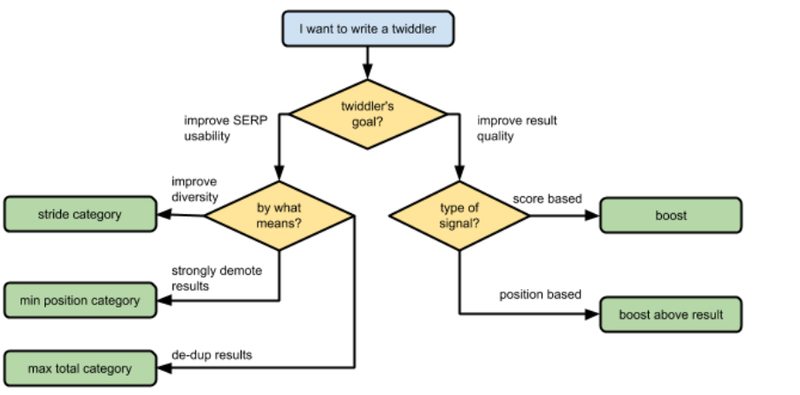
From Google’s Twiddler Quick Start Guide
In the DOJ vs Google trial, Pandu Nayak told us that Google’s AI system RankBrain re-ranks the top 20-30 results. I expect that twiddlers play a big role here.

From the DOJ vs Google trial testimony of Pandu Nayak
Types of Twiddlers
There are two types of Twiddlers:
Predoc twiddlers. These twiddlers are used for broad adjustments and work on a basic set of already ranked search results without detailed information such as SERP snippets or other information about the urls themselves. They can be used to promote certain pages or filter the results.
For example, the YouTubeDensityTwiddler might boost a channel’s main page if several of its videos are a good match for the query.
Lazy twiddlers. These twiddlers work on more complete information including snippets and other important information about a document. The document talks about lazy twiddlers using “docinfo”. While it doesn’t specifically say what info can be used, I expect that any information that is stored about a web page could be considered here. For example, the page title, the publication ****, author information, and structured data extracted from the page may be considered part of the docinfo.
I am speculating here, but it would not surprise me if any of the following can be used by lazy twiddlers:
- Entity recognition
- Page headings
- PageRank
- Anchor text information
- NavBoost signals of user engagement: clicks, long clicks, bad clicks and good clicks
- Chunks of content (see the end of this article for more on this)
Why Twiddlers matter
Some Twiddlers are used to Boost results that have been ranked using traditional information retrieval (IR) algorithms.
Twiddlers can be used to create a category and then apply actions to results within that category such as:
- Limiting the number of results from that category. For example, one Twiddler is called BlogCategorizer. It can categorize all blog posts to ensure that not too many are shown in the SERPs.
- Making it so results from that category only appear below a certain ranking position. For example, the BadURLsCategorizer Twiddler can be used to ensure that pages that have been flagged as demoted do not appear on the first couple of pages. The min_position category can be used to demote results to the second page. I expect that sites impacted by SpamBrain are impacted by this Twiddler. If you are finding you cannot crack page 1 no matter what you do, it’s possible you are being demoted by spam filtering Twiddlers.
- Identifying if a page is an official page and ensuring it ranks highly. There is a twiddler called OfficialPageTwiddler which can ensure an official page ranks near the top of the results.
- Ensuring that certain pages should appear in a certain order. An example of where the SetRelativeOrder Twiddler would be used is to make it so that the original version of a YouTube video always ranks higher than duplicates.
Twiddlers can also be used to remove or filter pages from the results. The EmptySnippetFilter twiddler filters out results that have no snippet. The DMCAFilter hides results for which Google has received a DMCA notice.
Twiddlers can also be used to annotate results. For example, the SocialLikesAnnotator annotates social results with the number of likes they have received. That is interesting!
How can SEOs use this information?
This is all fascinating information, but what can we do with a knowledge of Twiddlers to improve our SEO strategy? Here are a few thoughts:
Meta Descriptions matter
Some of the information used by twiddlers includes the snippet shown in the search results. This is usually your meta description, although Google can rewrite snippets to show in the SERPs. From this document on Twiddlers it seems to me that the information in your meta description could be used in some way in Twiddlers used to re-rank results. This is controversial though as John Mueller has specifically said that meta descriptions are not used in ranking. It’s possible that it’s not the meta description that is used, but rather, the relevant info that Google pulls from your page to use as a snippet (which is sometimes your meta description) that matters. Even if I’m wrong on this, the snippet shown in search results can influence user click behaviour, which we know is important to the Navboost system.
How I’m adjusting my SEO strategy: I’m paying closer attention to how enticing my clients’ snippets shown in search are compared to competitors. I’m focusing on writing meta descriptions that help a user decide that this page likely contains the answer to their query. In doing so, I’m understanding what’s important to user intent and crafting my meta description around that. I’m watching CTR in GSC and working on writing snippets that convince more people to click.
Diverse results matter. Be original.
There are Twiddlers used to filter out results that are similar. We know that originality is important to Google as it is the first point listed in their self assessment questions on creating helpful content.

When analyzing SERPs for keyword rankings it’s interesting to note how each result tends to offer something different to the searcher. I often use the analogy of a Librarian. If a searcher says, “Find me some resources to help me learn more about green widgets”, the Librarian may say, “OK, here’s a page from a brand known as a leader in this field, and here’s a page from a business lots of people buy from, and here’s a blog post that has an excellent buying guide…oh, and here’s this resource – from your site….” What is the Librarian going to say about your resource?

I have often noticed that there is only one, or perhaps just a few results in the top 10 that are informational. If I am trying to rank an informational page, my competition is not the full top 10 results. Rather, my goal is to be a better or more helpful resource than the sites that are ranking that meet a similar intent to mine.
If you haven’t yet read this patent on information gain, I’d highly recommend it.
How I’m adjusting my SEO strategy: I’m putting myself in the shoes of a searcher in studying the SERPs Google is choosing. If my client cannot be the official resource for this query, then we need to brainstorm on how we can clearly be a better choice than the similar sites that Google is ranking.
Put Yourself in the Shoes of a Searcher Workbook
Freshness matters
Have you read Google’s patent on Freshness based ranking? Their systems work to determine whether users tend to prefer fresh information for the topic they are searching on. This is likely something that makes use of Twiddlers that can re-rank results based on freshness.
Several of the attributes listed in the recently discovered API files relate to Freshness. These attributes are likely a part of the doc info that can be used by lazy twiddlers.
- creationDate
- lastUpdateTimestamp – used for freshness tracking
- encoded NewsAnchorData – scores are computed in regards to quality and freshness for news topics
How I’m adjusting my SEO strategy: I’m paying attention to the results in the SERPs to gauge whether Google is preferring fresh information. For most topics, users are likely to prefer fresh information. Even if the SERPs are not showing new, fresh info, I’m starting to experiment with updating information in older posts to add new, relevant information. I’m careful not to simply add new info just for the sake of ranking. It needs to be something that readers really will find helpful.
Google warns against trying to fake freshness in their helpful content documentation.
On a related note – “chunks” added as attributes
I’ve just noticed that there is an updated version of the attributes that are potentially used in search – version 0.6.0 contains new attributes talking about “chunks” which are sections of content. I expect that this information can likely be used in a number of ways in regards to ranking – perhaps by Twiddlers, but more likely, by vector search algorithms helping determine which content is likely to be relevant and helpful.

I’m currently experimenting with a few clients on better understanding user intent and optimizing content to look good for vector search as well as to searchers with specific intents. If you are interested in becoming a client so that I can test my theories on your content as well, contact me.



