
A comprehensive understanding of Spark’s transformation and action is crucial for efficient Spark code. This blog provides a glimpse on the fundamental aspects of Spark.
Before we deep dive into Spark’s transformation and action, let us see a glance of RDD and Dataframe.
Resilient Distributed Dataset (RDD): Usually, Spark tasks operate on RDDs, which is fault-tolerant partitions of simultaneous operations. RDDs are immutable (Once a RDD is created it cannot be changed).
Dataframe: A Dataframe is a Spark data structure that shares conceptual equivalence with a table in a relational database but incorporates more advanced optimizations internally. Structured data files such as external databases or existing RDDs, CSV, parquet etc., can be used to construct a Dataframe. The Dataframe is generated and manipulated through the Dataframe API.
Briefing Spark’s transformation and action:
RDDs facilitate two categories of operations: The Spark RDD operations are Transformation and Actions. Transformations, which create a new dataset from an existing one, and Actions, which return a value to the driver program after running a computation on the dataset.
Key Difference between transformations and actions: Transformations are business logic operations that do not induce execution while actions are execution triggers focused on returning results.
Transformations
In Spark, transformations handle creating a new dataset from an existing one. When a transformation is executed, it happens in single or multiple RDDs. Transformations are lazily evaluated i.e. It does not start until Spark action is called on RDD. Since RDD are immutable in nature, transformations always create new RDD without updating an existing one hence, this creates an RDD lineage.
Generally, Transformation is of two types:
- Narrow Transformations:
Narrow transformations are operations on RDDs where each input partition contributes to only a single output partition, often on the same executor. Narrow transformations allow Spark to execute computations within a single partition without needing to shuffle or redistribute data across the cluster. Examples of narrow transformations include map, filter, flatMap, union, distinct, coalesce etc.
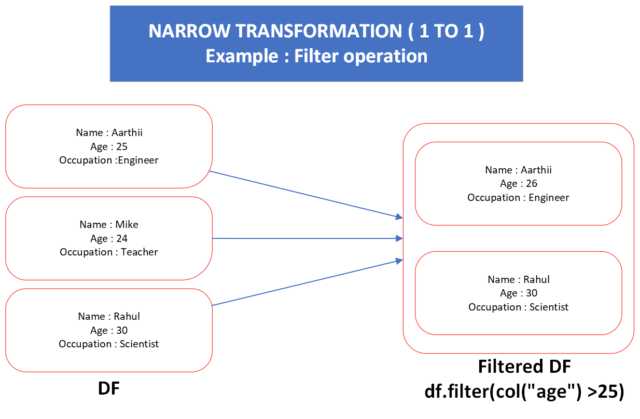
Use Cases:
- Operations that do not require shuffling or reorganization of data within partitions.
- Transformations like map, filter, flatMap, union, etc.
Best Practices:
- Preferred for processing within partitions without data movement.
- Efficient for simple transformations and when data locality is critical.
- Suitable for computations that don’t require data from multiple partitions.
-
Wide Transformations:
Wide transformations are operations on RDDs that require data from multiple partitions to create a single partition for the output. These transformations involve shuffling or redistributing data across partitions, potentially leading to a stage boundary or network communication between executors. Examples of wide transformations include groupByKey, reduceByKey, sortByKey, join, cogroup, repartition etc.
![]()
Use Cases:
- Operations involving data shuffling, such as groupBy, join, reduceByKey, sortByKey, etc.
- Aggregations, joins, or operations requiring data exchange between partitions.
Best Practices:
- Use when aggregating data across partitions or joining datasets on keys.
- Effective for operations that involve reshuffling or reorganizing data.
- Efficient for complex transformations requiring data from multiple partitions.
Key Differences:
- Dependency: Narrow transformations work independently within each partition, while wide transformations depend on data from multiple partitions.
- Shuffling: Narrow transformations avoid shuffling data across partitions, while wide transformations may involve shuffling data across the cluster.
- Parallelism: Narrow transformations allow Spark to execute tasks in parallel within partitions, leading to better performance in certain scenarios. Wide transformations may introduce a stage boundary, affecting parallelism and potentially causing performance overhead due to data shuffling.
Understanding these distinctions is crucial when designing Spark jobs to optimize performance and minimize unnecessary data shuffling, especially in large-scale distributed computing.
Actions
Actions are operations that trigger the execution of the Spark DAG (Directed Acyclic Graph) lineage created by transformations. When an action is called, Spark computes the results of the transformations and performs the necessary computations to return a result to the driver program or to persist data. Actions cause Spark to start computation on the RDDs and may trigger the execution of a job. Examples of actions include collect, count, saveAsTextFile, show, and more.
Best Practices:
- Avoid Unnecessary Actions: Limit actions to the essential steps. Unnecessary actions can trigger unnecessary computations, impacting performance.
- Action After Narrow Transformations: Prefer actions after narrow transformations to delay computations until necessary.
- Optimize Actions with Caching: Use caching or persistence to avoid recomputation of RDD/DataFrame if multiple actions are needed on the same dataset.
Actions Triggering Transformations:
- Lazy Execution Model: When invoked, actions like collect, count, or saveAsTextFile trigger the execution of the entire lineage of transformations leading up to that action in Spark’s lazy evaluation model, which postpones computation until an action is triggered.
- Action Execution: Spark analyzes the DAG, identifies the chain of transformations required to compute the result, and schedules the execution plan across the cluster when it calls an action.
Exploring Common Spark Transformations & Actions
Below are some examples illustrating various Spark transformations and actions along with explanations of their behaviors in Spark using Scala.
Creating a common dataset:

Narrow Transformations:
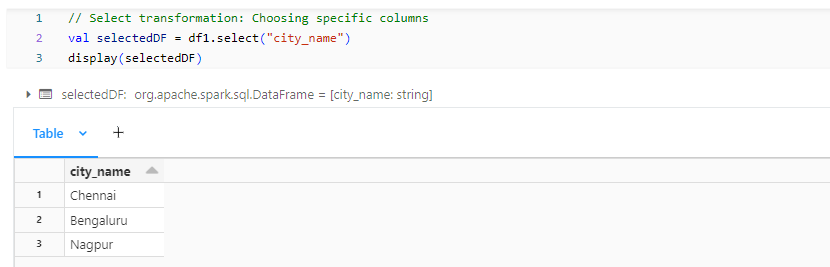
- selectedDF: Select transformation narrows down the columns.
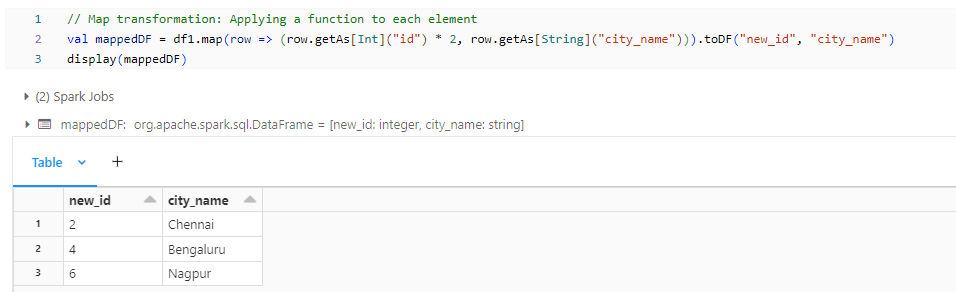
- mappedDF: Map transformation applies a function to each element within partitions.
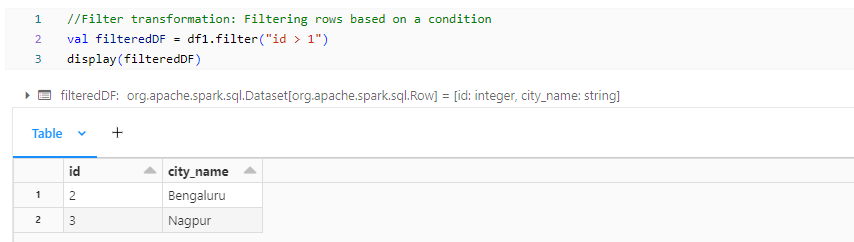
- filteredDF: Filter transformation operates on each partition independently.
Wide Transformations:
- unionedDF: Union transformation combines data from two Dataframe, potentially across partitions.
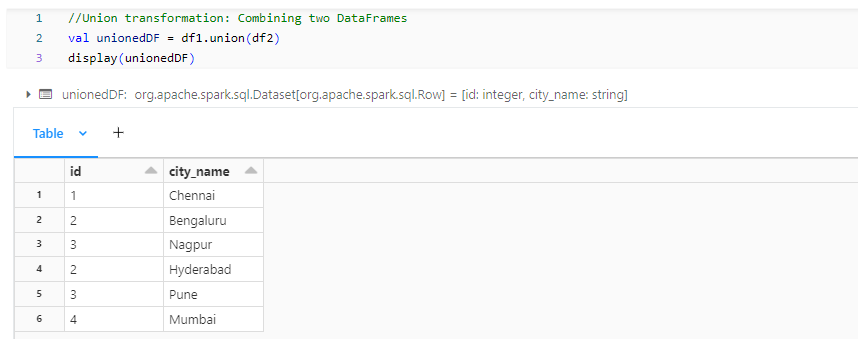
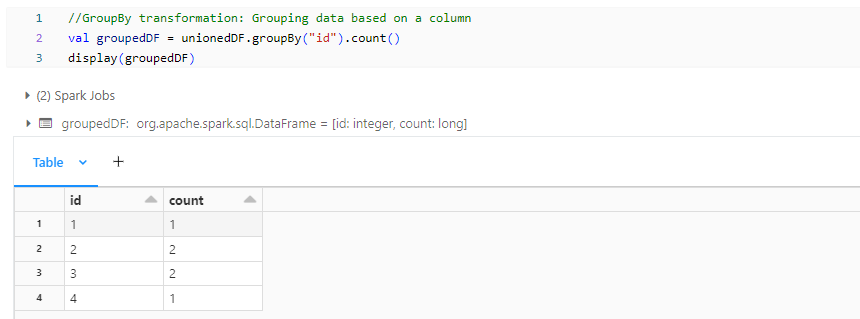
- groupedDF: GroupBy transformation groups data by a column, potentially shuffling data across partitions.
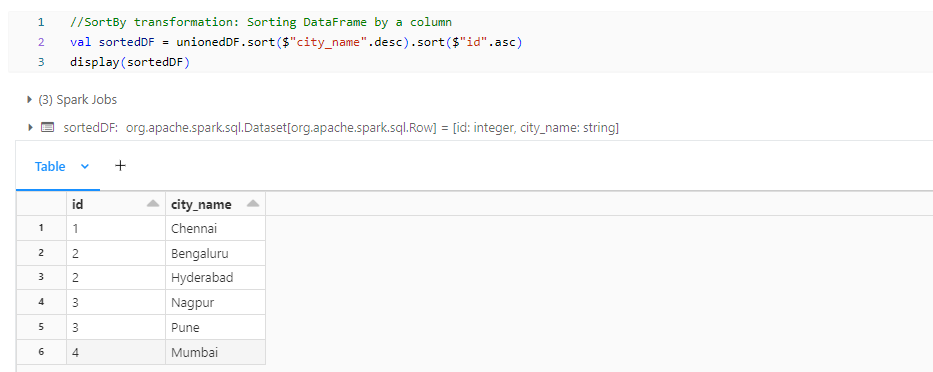
- sortedDF: SortBy transformation reorders data, across partitions, based on the specified column.
Actions:
- collectedData: Collect action retrieves all Dataframe records to the driver.

- count: Count action counts the number of records in the Dataframe.

- firstRecord: First action retrieves the first record of the DataFrame.

- firstTwoRecords: Take action retrieves the first ‘n’ records as an array.

Summary:
To summarize, Spark RDD Operations are Transformations and Actions. Transformations specify the alterations to RDDs without immediate computation, while actions start the execution of these transformations, yielding a result.
Consider in Spark, applying transformations such as map, filter, and groupBy to an RDD. These transformations remain dormant until an action, like collect or count is triggered. At that juncture, Spark processes the transformations carrying out the necessary computations to yield the output or perform designated operations.



