
Since the introduction of generative AI, large language ****** (LLMs) have conquered the world and found their way into search engines.
But is it possible to proactively influence AI performance via large language model optimization (LLMO) or generative AI optimization (GAIO)?
This article discusses the evolving landscape of SEO and the uncertain future of LLM optimization in AI-powered search engines, with insights from data science experts.
What is LLM optimization or generative AI optimization (GAIO)?
GAIO aims to help companies position their brands and products in the outputs of leading LLMs, such as GPT and Google Bard, prominent as these ****** can influence many future purchase decisions.
For example, if you search Bing Chat for the best running shoes for a 96-kilogram runner who runs 20 kilometers per week, Brooks, Saucony, Hoka and New Balance shoes will be suggested.
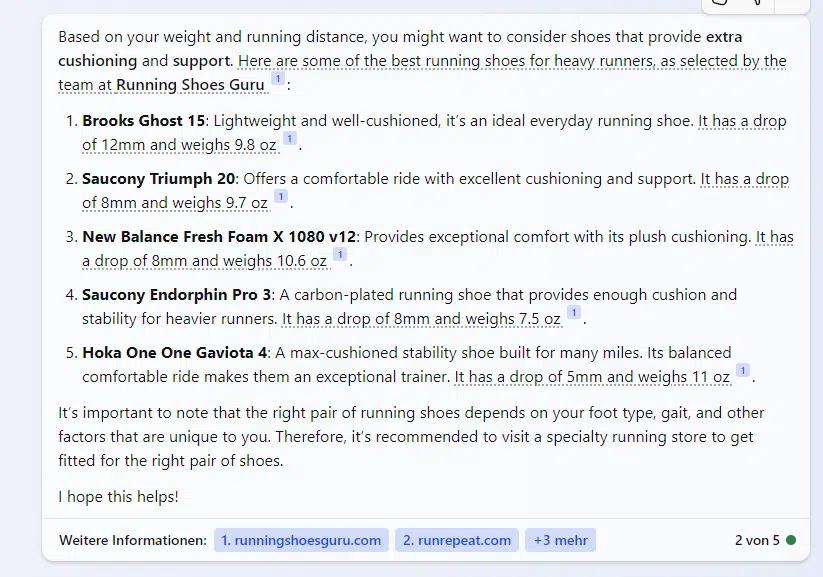
When you ask Bing Chat for safe, family-friendly cars that are big enough for shopping and travel, it suggests Kia, Toyota, Hyundai and Chevrolet ******.
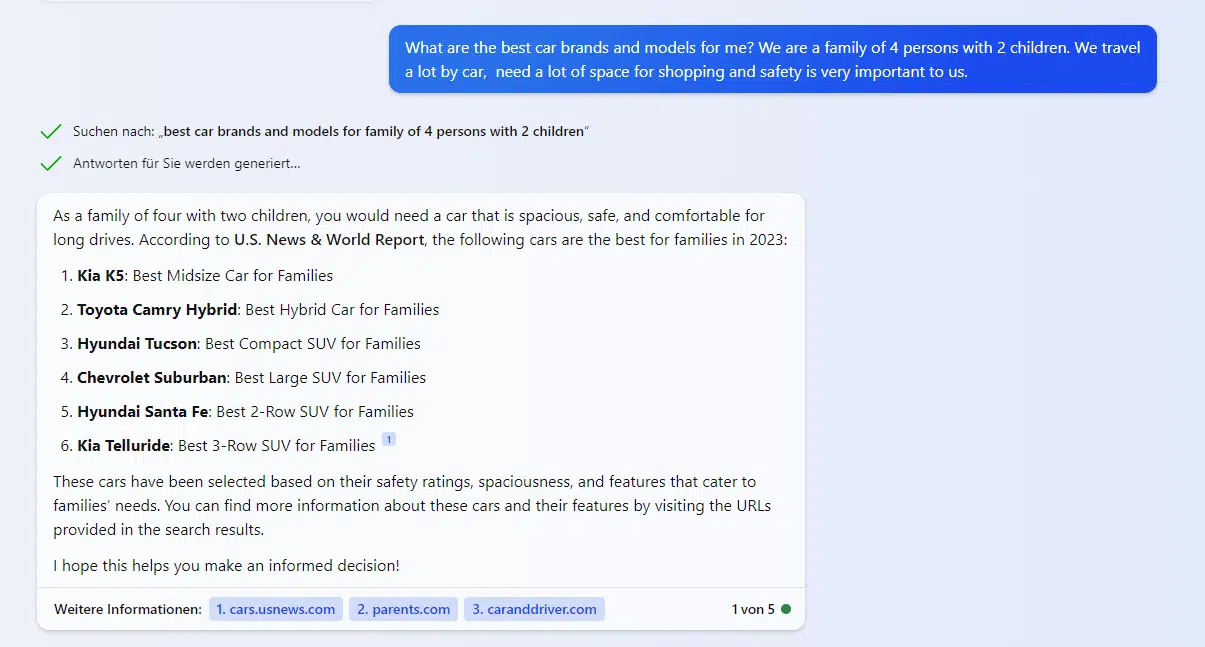
The approach of potential methods such as LLM optimization is to give preference to certain brands and products when dealing with corresponding transaction-oriented questions.
How are these recommendations made?
Suggestions from Bing Chat and other generative AI tools are always contextual. The AI mostly uses neutral secondary sources such as trade magazines, news sites, association and public institution websites, and blogs as a source for recommendations.
The output of generative AI is based on the determination of statistical frequencies. The more often words appear in sequence in the source data, the more likely it is that the desired word is the correct one in the output.
Words frequently mentioned in the training data are statistically more similar or semantically more closely related.
Which brands and products are mentioned in a certain context can be explained by the way LLMs work.
LLMs in action
Modern transformer-based LLMs such as GPT or Bard are based on a statistical analysis of the co-occurrence of tokens or words.
To do this, texts and data are broken down into tokens for machine processing and positioned in semantic spaces using vectors. Vectors can also be whole words (Word2Vec), entities (Node2Vec), and attributes.
In semantics, the semantic space is also described as an ontology. Since LLMs rely more on statistics than semantics, they are not ontologies. However, the AI gets closer to semantic understanding due to the amount of data.
Semantic proximity can be determined by Euclidean distance or cosine angle measure in semantic space.

If an entity is frequently mentioned in connection with certain other entities or properties in the training data, there is a high statistical probability of a semantic relationship.
The method of this processing is called transformer-based natural language processing.
NLP describes a process of transforming natural language into a machine-understandable form that enables communication between humans and machines.
NLP comprises natural language understanding (NLU) and natural language generation (NLG).
When training LLMs, the focus is on NLU, and when outputting AI-generated results, the focus is on NLG.
Identifying entities via named entity extraction plays a special role in semantic understanding and an entity’s meaning within a thematic ontology.
Due to the frequent co-occurrence of certain words, these vectors move closer together in the semantic space: the semantic proximity increases, and the probability of membership increases.
The results are output via NLG according to statistical probability.
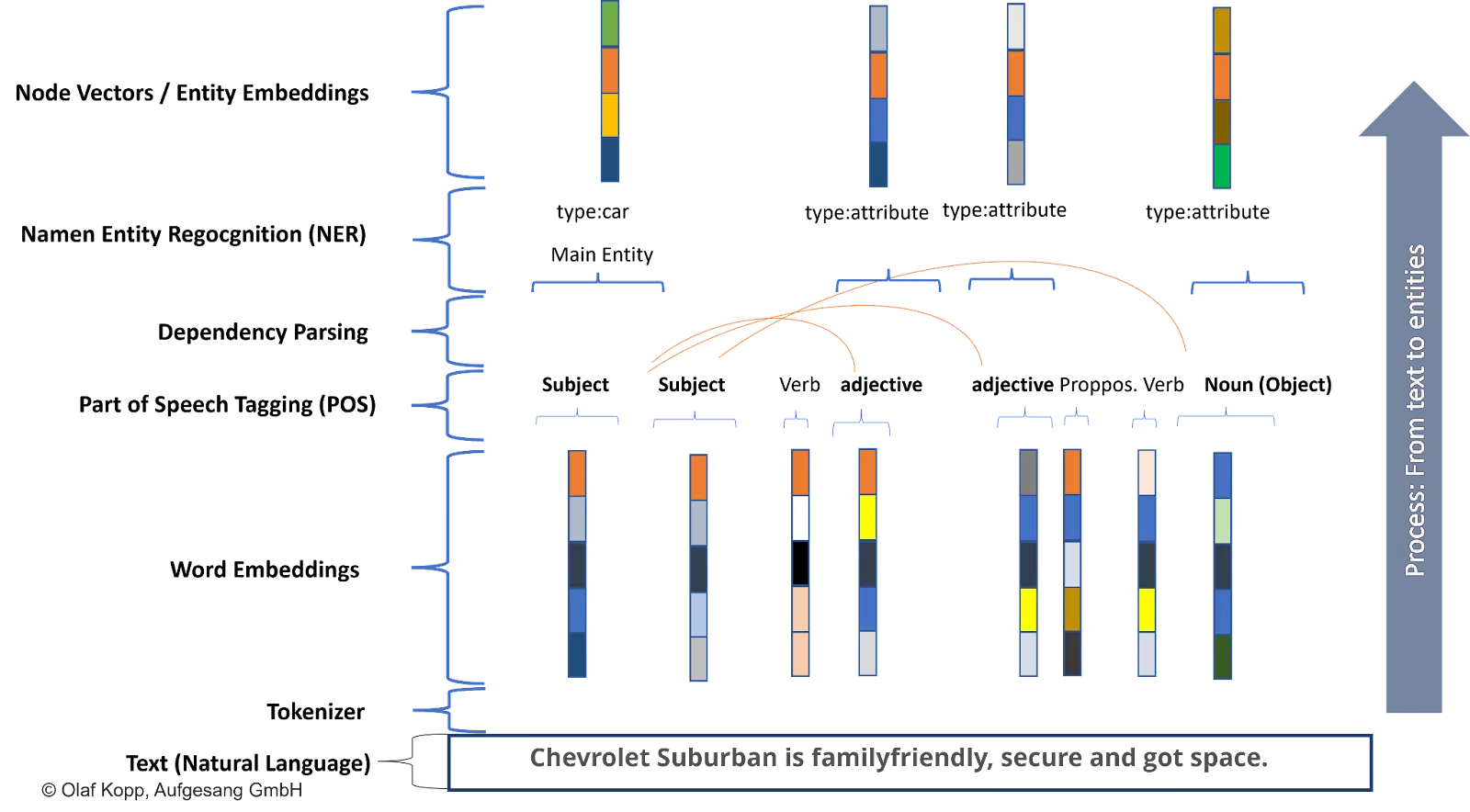
For example, suppose the Chevrolet Suburban is often mentioned in the context of family and safety.
In that case, the LLM can associate this entity with certain attributes such as safe or family-friendly. There is a high statistical probability that this car model is associated with these attributes.
Get the daily newsletter search marketers rely on.
Can the outputs of generative AI be influenced proactively?
I haven’t heard conclusive answers to this question, only unfounded speculation.
To get closer to an answer, it makes sense to approach it from a data science perspective. In other words, from people who know how large language ****** work.
I asked three data science experts from my network. Here’s what they said.
Kai Spriestersbach, Applied AI researcher and SEO veteran:
- “Theoretically, it’s certainly possible, and it cannot be ruled out that political actors or states might go to such lengths. Frankly, I actually assume some do. However, from a purely practical standpoint, for business marketing, I don’t see this as a viable way to intentionally influence the “opinion” or perception of an AI, unless it’s also influencing public opinion at the same time, for instance, through traditional PR or branding.
- “With commercial large language ******, it is not publicly disclosed what training data is used, nor how it is filtered and weighted. Moreover, commercial providers utilize alignment strategies to ensure the AI’s responses are as neutral and uncontroversial as possible, irrespective of the training data.
- “Ultimately, one would have to ensure that over 50% of the statements in the training data reflect the desired sentiment, which in the extreme case means flooding the net with posts and texts, hoping they get incorporated into the training data.”
Barbara Lampl, Behavioral mathematician and COO at Genki:
- “It’s theoretically possible to influence an LLM through a synchronized effort of content, PR, and mentions, the data science mechanics will underscore the increasing challenges and diminishing rewards of such an approach.
- “The endeavor’s complexity, when analyzed through the lens of data science, becomes even more pronounced and arguably unfeasible.”
Philip Ehring, Head of Business Intelligence at Reverse-Retail:
- “The dynamics between LLMs and systems like ChatGPT and SEO ultimately remain the same at the end of the equation. Only the perspective of optimization will switch to another tool, that is in fact nothing more than a better interface for classical information retrieval systems…
- “In the end, it’s an optimization for a hybrid metasearch engine with a natural language user interface that summarizes the results for you.”
The following points can be made from a data science perspective:
- For large commercial language ******, the training database is not public, and tuning strategies are used to ensure neutral and uncontroversial responses. To embed the desired opinion in the AI, more than 50% of the training data would have to reflect that opinion, which would be extremely difficult to influence.
- It is difficult to make a meaningful impact due to the huge amount of data and statistical significance.
- The dynamics of network proliferation, time factors, model regularization, feedback loops, and economic costs are obstacles.
- In addition, the delay in model updates makes it difficult to influence.
- Due to the large number of co-occurrences that would have to be created, depending on the market, it is only possible to influence the output of a generative AI with regard to one’s own products and brand with greater commitment to PR and marketing.
- Another challenge is to identify the sources that will be used as training data for the LLMs.
- The core dynamics between LLMs and systems like ChatGPT or BARD and SEO remain consistent. The only change is in the optimization perspective, which shifts to a better interface for classical information retrieval.
- ChatGPT’s fine-tuning process involves a reinforcement learning layer that generates responses based on learned contexts and prompts.
- Traditional search engines like Google and Bing are used to target quality content and domains like Wikipedia or GitHub. The integration of ****** like BERT into these systems has been a known advancement. Google’s BERT changes how information retrieval understands user queries and contexts.
- User input has long directed the focus of web crawls for LLMs. The likelihood of an LLM using content from a crawl for training is influenced by the document’s findability on the web.
- While LLMs excel at computing similarities, they aren’t as proficient at providing factual answers or solving logical tasks. To address this, Retrieval-Augmented Generation (RAG) uses external data stores to offer better, sourced answers.
- The integration of web crawling offers dual benefits: improving ChatGPT’s relevance and training, and enhancing SEO. A challenge remains in human labeling and ranking of prompts and responses for reinforcement learning.
- The prominence of content in LLM training is influenced by its relevance and discoverability. The impact of specific content on an LLM is challenging to quantify, but having one’s brand recognized within a context is a significant achievement.
- RAG mechanics also improve the quality of responses by using higher-ranked content. This presents an optimization opportunity by aligning content with potential answers.
- The evolution in SEO isn’t a completely new approach but a shift in perspective. It involves understanding which search engines are prioritized by systems like ChatGPT, incorporating prompt-generated keywords into research, targeting relevant pages for content, and structuring content for optimal mention in responses.
- Ultimately, the goal is to optimize for a hybrid metasearch engine with a natural language interface that summarizes results for users.
How could the training data for the LLMs be selected?
There are two possible approaches here: E-E-A-T and ranking.
We can assume that the providers of the well-known LLMs only use sources as training data that meet a certain quality standard and are trustworthy.
There would be a way to select these sources using Google’s E-E-A-T concept. Regarding entities, Google can use the Knowledge Graph for fact-checking and fine-tuning the LLM.

The second approach, as suggested by Philipp Ehring, is to select training data based on relevance and quality determined by the actual ranking process. So, top-ranking content to the corresponding queries and prompts are automatically used for training the LLMs.
This approach assumes that the information retrieval wheel does not have to be reinvented and that search engines rely on established evaluation procedures to select training data. This would then include E-E-A-T in addition to relevance evaluation.
However, tests on Bing Chat and SGE have not shown any clear correlations between the referenced sources and the rankings.
Influencing AI-powered SEO
It remains to be seen whether LLM optimization or GAIO will really become a legitimate strategy for influencing LLMs in terms of their own goals.
On the data science side, there is skepticism. Some SEOs believe in it.
If this is the case, there are the following goals that need to be achieved:
- Establish your own media via E-E-A-T as a source of training data.
- Generate mentions of your brand and products in qualified media.
- Create co-competitions of your own brand with other relevant entities and attributes in qualified media.
- Become part of the knowledge graph.
I have explained what measures to take to achieve this in the article How to improve E-A-T for websites and entities.
The chances of success with LLM optimization increase with the size of the market. The more niche a market is, the easier it is to position yourself as a brand in the respective thematic context.
This means that fewer co-occurrences in the qualified media are required to be associated with the relevant attributes and entities in the LLMs. The larger the market, the more difficult this is, as many market participants have large PR and marketing resources and a long history.
GAIO or LLM optimization requires significantly more resources than classic SEO to influence public perception.
At this point, I would like to refer to my concept of Digital Authority Management. You can read more about this in the article Authority Management: A New Discipline in the Age of SGE and E-E-A-T.
Suppose LLM optimization turns out to be a sensible SEO strategy. In that case, large brands will have significant advantages in search engine positioning and generative AI results in the future due to their PR and marketing resources.
Another perspective is that one can continue in search engine optimization as before since well-ranking content can also be used for training the LLMs simultaneously. There, one should also pay attention to co-occurrences between brands/products and attributes or other entities and optimize for them.
However, tests on Bing Chat and SBU have not yet shown clear correlations between referenced sources and rankings.
Which of these approaches will be the future for SEO is unclear and will only become apparent when SGE is finally introduced.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Source link : Searchengineland.com

![YMYL Websites: SEO & EEAT Tips [Lumar Podcast]](https://www.lumar.io/wp-content/uploads/2024/11/thumb-Lumar-HFD-Podcast-Episode-6-YMYL-Websites-SEO-EEAT-blue-1024x503.png "YMYL Websites: SEO & EEAT Tips [Lumar Podcast]")

