
In 2006, Tim Berners-Lee had a vision of building a semantic web enabled through Linked Data. Now, more than ever before, his vision is becoming a reality, because in addition to humans, AI and Large Language ****** need this data to deliver on new experiences.
In this article, we’ll explore what Linked Data is and share examples of Linked Data projects which many in the SEO and tech community refer to as knowledge graphs.
What is Linked Data?
Linked Data is a set of design principles for publishing machine-readable interconnected data on the web.
The term “Linked Data” first appeared in 2006 when Tim Berners-Lee published a design note about the Semantic Web. He sought to use Linked Data as a way of representing the relationship between different things on the internet. The internet would then become a huge database of interconnected (linked) objects (data) and become the Semantic Web.
Businesses or enterprises can use Linked Data to define things and the relationships between them. For example, companies like Facebook, Twitter, and LinkedIn have undertaken Linked Data projects to represent social networks. When users perform actions like connecting to other users or liking and resharing content, these actions are reflected in a graphical representation of who they are, who they know and what they like.
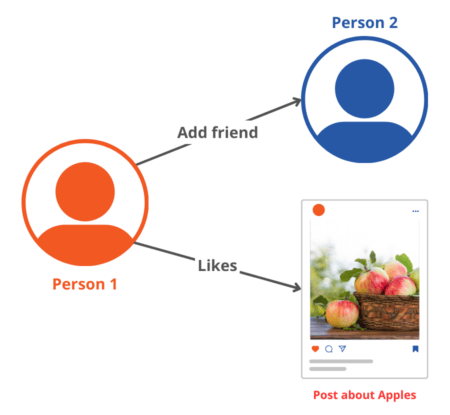
As a result, these social media platforms can gain knowledge about a person and enable things like targeted advertising to users based on their relationship to other things. However, the knowledge that these social media platforms derive from their Linked Data is proprietary and not licensed for external use.
This led to a movement calling for Linked Data to be open for people to use freely for research purposes – especially from governmental organizations, and other public institutions such as museums.
In 2010, Tim Berners-Lee modified his original design note to add principles for Linked Open Data, a variation of Linked Data permitting reuse.
Linked Open Data (LOD) is Linked Data released under an open license, which allows others to freely access and reuse it.
Principles of Linked Data
When Tim Berners-Lee first published the design note about Linked Data, he defined the 4 principles of Linked Data. Based on this note, people or machines would be able to explore the web of data if it adhered to the following 4 principles:
1. Use URIs as names for things
A URI (Uniform Resource Identifier) is a string of characters that identifies a resource. It provides a consistent way to identify resources across different systems and protocols. A resource (also known as an entity) is anything that can be identified and described, such as people, places, objects, or concepts.
2. Use HTTP [or HTTPS] URIs so that people can look up those names
An HTTP/HTTPS URI is a specific type of URI that uses the Hypertext Transfer Protocol or Protocol Secure. This means that when you access an HTTP/HTTPS URI in a web browser or through an HTTP request, you should get back information about the resource it identifies.
3. When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL)
When a user or application accesses a Uniform Resource Identifier (URI), the information returned should be both meaningful and structured according to standardized semantic technologies, specifically RDF (for expressing the data) and SPARQL (for querying the data).
4. Include links to other URIs so that they can discover more things
When you create or publish data, you should include links within your data to other resources or entities (in the form of URIs). These URIs can point to related or relevant information, such as other resources, definitions, or attributes. This provides additional context about your own resources.
By following these principles, you contribute to a growing network of interlinked data across the web. This allows consumers of the data (human or machine) to gather more insights, context, and knowledge.
The benefit of using Linked Data for SEO
Linked Data is great for SEO because it can provide search engines with more contextual knowledge about your content. Search engines now look at relevancy to provide searchers with the most accurate results.
One of the most common forms of linked data on the web is Schema Markup which primarily describes webpage contents for search engines. Schema Markup uses the Schema.org vocabulary which can express RDF linked data in formats like JSON-LD.
When you use machine-readable code like Schema Markup to express the relationship between the entities on your site, it helps search engines understand and derive knowledge about your organization.
For example, if you have a page about your organization’s proprietary software application, you can tell search engines that this software application is provided by your organization by linking the URI that contains all the information about your organization to the provider property in the markup for your page.
{
"@context": "http://schema.org/",
"@type": "SoftwareApplication",
"@id": "https://www.schemaapp.com/solutions/schema-app-highlighter/#SoftwareApplication",
"name": "Schema App Highlighter",
"description": "Use the Schema App Highlighter to customize your Schema Markup...",
"applicationCategory": "Search Engine Optimization",
"provider": {
"@type": "Organization",
"@id": "https://www.schemaapp.com/#Organization",
"url": "https://www.schemaapp.com/",
"name": "Schema App",
"description": "Schema App is an end-to-end Schema Markup solution...",
"telephone": "18554448624",
"email": "[email protected]",
"areaServed": "http://www.wikidata.org/entity/Q13780930",
}
}
The URI appears in JSON-LD in the @id attribute. Your Schema Markup can be generated and authored without including identifiers (@id). Search engines like Google will still read it and make it eligible for rich results. However, by generating your Schema Markup with a URI, you can link it to other entities.
You can also link your Schema Markup to other Linked Data projects to be more explicit about the entities you are talking about on your website.
For example, if you are talking about football on a page, this can be confusing to search engines because the term football can mean different things depending on where you are in the world. You can help search engines disambiguate which football you are referring to by linking your page to the same entity described in Wikipedia, Wikidata or Google’s Knowledge Graph.
If you are talking about American football, you can use the sameAs property in your Schema Markup to link to the same entity on Wikipedia, Wikidata or Google’s Knowledge graph.
{
"@context": "http://schema.org/",
"@type": "BlogPosting",
"@id": "https://www.schemaapp.com/blog/what-is-football/#BlogPosting",
"url": "https://www.schemaapp.com/blog/what-is-football/",
"name": "What is Football?",
"headline": "What is Football?",
"description": "Learn about the rules and history of Football.",
"mentions": {
"@type": "Thing",
"name": "Football",
"sameAs": "https://www.wikidata.org/wiki/Q41323",
"sameAs": "https://en.wikipedia.org/wiki/American_football",
"sameAs": "kg:/m/0jm_",
}
}
However, applying Linked Data on your site can be a technically challenging task.
- Quality – You need to keep the data up-to-****, accurate and complete.
- Scalability – Handling this huge volume of data can be time-consuming and resource-intensive.
- Expertise – Transforming your content into Linked Data requires knowledge of the technologies to do this work and how to apply them effectively.
- Sustainability – You need resources to maintain the data quality.
Examples of Linked Data Projects in SEO
There are many examples of Linked Data Projects in use today. These Linked Data Projects are also often referred to as Knowledge Graphs.
Knowledge graphs are a collection of related entities expressed as RDF triples. When you use Schema Markup to express the relationship between two entities on your site, you are implementing Linked Data. When you connect the various entities on your site, you are effectively developing an internal knowledge graph about your organization. Your internal knowledge graph becomes even more robust and useful when linked to other external knowledge graphs.
Some of these external knowledge graphs are also useful for search engine optimization (SEO) purposes. SEO teams can connect their internal knowledge graphs to external knowledge graphs to tell search engines that the entity defined in this external knowledge graph is the same as the entity defined on their website.
Let’s explore some of the Linked Data Projects / External Knowledge Graphs pertaining to the SEO world.
Google’s Knowledge Graph
Google’s Knowledge Graph is a knowledge database that Google uses to provide quick answers to queries about certain topics or entities (people, places, organizations, things). This can show up in search in the form of a knowledge panel. The knowledge panel contains a snapshot of information about the topic based on Google’s understanding of the available content on the internet.

The story of Google’s Knowledge Graph starts with Freebase, a Metaweb project launched in 2007. Freebase was described as “a system for building the synapses for the global brain”. This massive knowledge base, which formally became a linked open data project in 2008, was one of the largest and most ambitious Linked Data projects of its time.
In 2010, Google acquired Freebase from Metaweb and imported Freebase’s massive knowledge base into Google’s proprietary Knowledge Graph. Soon after, Google introduced their Knowledge Graph in their famous ‘things, not strings’ article, indicating a pivot from lexical to semantic search.
The Google Knowledge Graph is a Linked Data project because it adheres to the 4 principles of Linked Data. However, the Google Knowledge Graph is NOT a linked open data project because the data is not published with an open license. That being said, it is possible to find identifiers (URIs) for entities in the Google Knowledge Graph and link them to your own knowledge graph.
How to access Google’s Knowledge Graph?
The Google Knowledge Graph has a search API that is read-only. You’ll notice the URIs in the output are structured with a “kg” namespace (which stands in for http://g.co/kg) and either /m/ or /g/ before a string of characters. These identifiers are called “mid”s, or Machine IDs, which is a legacy term from Freebase.
For example, the Freebase object for the entity Barack Obama has the mid /m/02mjmr. This same entity can be accessed in Google’s Knowledge Graph by going to https://www.google.com/search?kgmid=/m/02mjmr. The entity has the same mid in Google’s Knowledge Graph.
How is Google’s Knowledge Graph used?
Google uses its knowledge graph to improve the search experience on its search engine. When you search for something like “Berkshire Hathaway”, Google identifies the entities in your query and provides information on those entities from both its knowledge graph and other sources on the web. One of the most common sources is Wikipedia.
Wikipedia & DBpedia
Wikipedia is a free, collaborative online encyclopedia composed of more than 61 million articles. Wikipedia articles represent entities, such as people, places, events, concepts, or other things.
The URLs of Wikipedia articles also function as URIs for the entities they represent. So the URL https://en.wikipedia.org/wiki/Kathryn_Janeway is both an article that can be visited on the web, and the URI that represents the entity, Kathryn Janeway, in Wikipedia’s knowledge base.
Articles within Wikipedia contain structured elements, as well as links to other related entities. While Wikipedia on its own isn’t a traditional Linked Data project, it plays a significant role in the Linked Data ecosystem on the web, particularly with regard to DBpedia and Wikidata.
DBpedia is a linked open data project that extracts information from Wikipedia to generate RDF triples, which can be semantically queried alongside other related datasets. It pulls information from the structured elements of Wikipedia pages, such as “infobox” tables like this:
While Wikipedia might be an excellent source of summarized information for general use, the depth and breadth of information on Wikipedia means it has become an essential source of training data for many AI initiatives such as natural language processing, named entity recognition, and the development of Knowledge Graphs like Google’s Knowledge Graph.
 Post from Wikipedia Engineering Manager, Joseph S.; inspired by https://xkcd.com/2347/
Post from Wikipedia Engineering Manager, Joseph S.; inspired by https://xkcd.com/2347/
Wikidata
Wikidata is a collaborative Linked Open Data project that’s been operated by the Wikimedia Foundation since its inception in 2012 (source).
Despite having Wiki in its name, Wikidata is not the same as Wikipedia. Wikidata is a broader knowledge base than Wikipedia, containing data about a wider range of topics. Wikidata also allows users to create RDF Linked Data directly.
Even though Wikidata and DBpedia are both Linked Open Data projects related to Wikipedia, they have different aims and serve different functions.
DBpedia extracts information to generate Linked Data from Wikipedia’s structured sources like infoboxes. As a result, DBpedia treats the knowledge derived as facts.
Rather than extracting information from Wikipedia, Wikidata creates Linked Data for Wikipedia (source). Since Wikidata also treats statements within the Linked Data as claims rather than facts, these statements must be annotated with provenance information (i.e. who made each claim).
Instead of “mid”s (identifiers used by Freebase/Google’s Knowledge Graph), each entity in Wikidata has a “qid”.
Here’s a summary of the identifiers for each of the Linked Data projects listed above.
Google’s Knowledge Graph, Wikipedia, and Wikidata are the most common Linked Data projects utilized in SEO. When we talk about connecting your Schema Markup to external authoritative knowledge bases at Schema App, these are the external knowledge graphs we are referring to.
How to use Linked Data with Schema App
At Schema App, our semantic technologies allow SEO teams to easily generate Linked Data for their website content.
Generate URIs for your entities
When you publish your Schema Markup using the Schema App Editor or Highlighter, our tool automatically generates HTTPS URIs for the entities you define in your Schema Markup. These URIs, which appear in the @id attribute, link to the URLs of the pages where they’ve been mentioned.
For example, we publish Organization markup to our Schema App home page. The URI for our Organization entity would then be the URL of our homepage + #Organization – https://www.schemaapp.com/#Organization. If you navigate to this URI, it will take you to the page about our Organization.
Creating URIs for entities on your site allows you to easily link to those entities in your Schema Markup. For example, if your organization has published a blog post you can link your Organization URI to the publisher property in your BlogPosting Schema Markup.
{
"@context": "http://schema.org/",
"@type": "BlogPosting",
"@id": "https://www.schemaapp.com/schema-markup/what-is-a-rich-result/#BlogPosting",
"url": "https://www.schemaapp.com/schema-markup/what-is-a-rich-result/",
"name": "What is a Rich Result?",
"headline": "What is a Rich Result?",
"description": "A rich result is an enhanced search result shown on search engine results page. Find out how you can achieve a rich result for your page.",
"publisher": {
"@type": "Organization",
"@id": "https://www.schemaapp.com/#Organization",
"url": "https://www.schemaapp.com/",
"name": "Schema App",
"description": "Schema App is an end-to-end Schema Markup solution...",
"telephone": "18554448624",
"email": "[email protected]",
"areaServed": "http://www.wikidata.org/entity/Q13780930",
}
}
Linking to external entities
Our tools also allow SEO teams to link to external entities using a variety of methods such as:
You can read this article to learn more about our entity linking methods.
Overcome the challenges of implementing Linked Data
In summary, Linked Data facilitates the connection of data from different sources to provide machines with more contextual information, enabling them to infer new knowledge from existing facts.
Applying Linked Data through the Schema Markup on your site can help search engines understand the relationship between the entities on your site and disambiguate the entities mentioned in your content.
If you need help implementing Linked Data on your site, we can help. At Schema App, we provide SEO teams with the tools and expertise to implement Linked Data at scale. Get in touch with us to learn more.

Jasmine is the Product Enablement Lead at Schema App. Schema App is an end-to-end Schema Markup solution that helps enterprise SEO teams create, deploy and manage Schema Markup to stand out in search.



