
Introduction:
Apache Kafka is a distributed streaming platform that enables businesses to build real-time streaming applications. First developed at LinkedIn in 2010, it has become one of the most widely used messaging systems for big data and real-time analytics. Kafka can process and transmit massive amounts of data in real-time, and its design ensures fault tolerance, scalability, and high availability. It uses a publish-subscribe model for communication between producers and consumers. Producers publish messages to Kafka topics, and consumers subscribe to these topics to receive the messages. In this blog, we will discuss how Kafka works and how to load Kafka data into MongoDB.
Kafka main components:
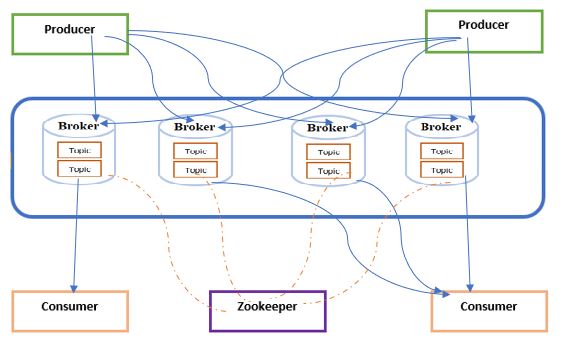
Four main components make up Kafka: producers, topics, brokers, and consumers.
Producers:
Messages are sent to Kafka topics by applications known as producers, which are logical categories that can be thought of as message queues.
When a producer sends a message to Kafka, it specifies the topic and message contents. Kafka stores the messages in its distributed log and makes them available to consumers.
Topics:
Topics are the categories or channels that messages are published to. They can have one or many producers and one or many consumers.
Brokers:
Brokers are servers that store and distribute messages. They manage the data replication and provide fault-tolerance.
Consumers:

Consumers are applications that read data from Kafka. These applications subscribe to one or more topics and receive messages as Kafka publishes them.

Consumers can read messages in two ways:
- Sequential reading: The consumer reads messages in the order of their production, one at a time.
- Parallel reading: Consumer reads messages from multiple partitions simultaneously, which can increase performance.
How to load Kafka data into MongoDB:
Consumers actively subscribe to Kafka topics and read messages from the distributed log. Kafka assigns a specific set of partitions to each consumer for reading. Each partition can be read by only one consumer, ensuring that messages are processed in the order they were produced.
Kafka utilizes a pull-based model for consumers. that means consumers request messages from Kafka, rather than Kafka pushing messages to consumers. Consumers can specify a starting offset, which indicates the position in the Kafka log where they want to start reading messages.This feature empowers consumers to read only the messages that interest them and prevents them from consuming duplicate messages.
Kafka supports parallel processing of messages through the use of partitions. Only one consumer can read each partition, but multiple consumers can read from multiple partitions in parallel.This feature allows for better performance and scalability when multiple consumers are reading from the same topic.
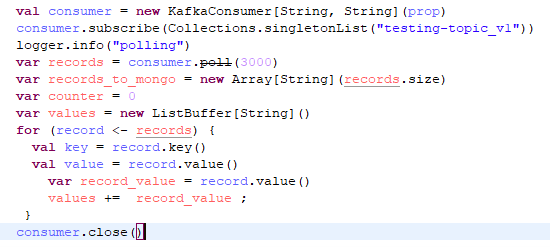
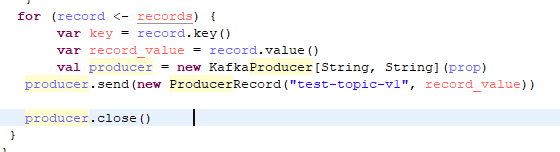
To load Kafka data into MongoDB, the consumer reads the data and collects the values.
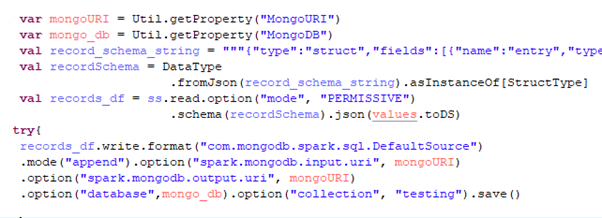
The code in this example reads messages from a Kafka topic named “testing-topic-v1”, parses the JSON message payload utilizing the read method, and then inserts the resulting JSON data into a MongoDB collection titled “testing” via the save method. Prior to loading the data into MongoDB,the schema is verified using Spark’s StructType and StructField.
Conclusion:
Kafka is a distributed streaming platform that can process vast amounts of data in real-time, making it a powerful tool for building flexible and scalable real-time streaming applications capable of processing and analyzing data as it’s generated. Its fault-tolerance, scalability, and high availability make Kafka a popular choice for numerous big data and real-time analytics use cases.
Please refer to the links below for more details:
What is Apache Kafka®? | Confluent
MongoDB Connector for Spark — MongoDB Spark Connector
Happy Learning!!



