
How to fix “Crawled – Currently Not Indexed” – 5 simple steps!
Google doesn’t give a clear answer as to why a given page was crawled but not indexed, but there are a few possible reasons why the status might appear. Learn how to fix this issue with the following steps.
STEP 1: Provide high-quality content
As a website owner, you should ensure your page provides high-quality content. Check if it’s likely to satisfy your users’ intent and add good quality content if needed. Google Search Central offers a list of questions to help you determine the value of your content:
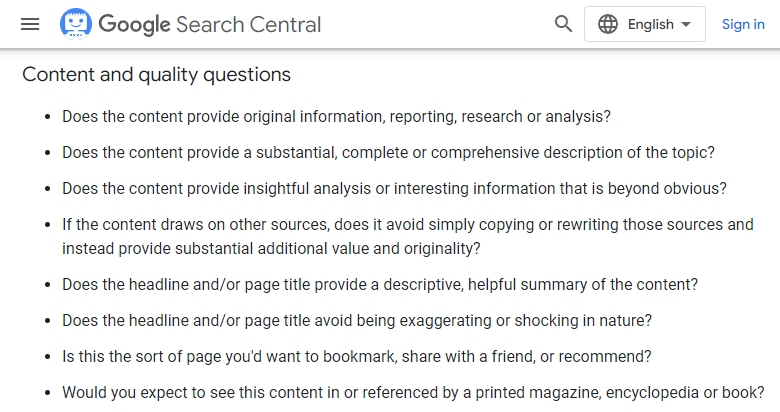
Additionally, you can use tips on quality content from Google’s Quality Raters Guidelines. Even though the document is meant mainly for Search Quality Raters to assess the quality of a website, webmasters can use it to get some insights on how to improve their sites. To learn more, check out our article on the Quality Rater Guidelines.
Another aspect to focus on is optimizing the user-generated content on your website.
For example, let’s assume you have a forum, and someone asks a question. Even though there might be many valuable replies in the future, there were none at the time of crawling, so Google may classify the page as low-quality content.
What should you do to protect yourself from this situation? Read my article to find out what Quora’s strategy was to solve this problem.
Remember that Google can’t index all of the pages on the Internet. Its storage space is limited, so it needs to filter out the low-quality content.
Google’s goal is to provide the highest quality pages that best answer users’ intent. If a page is of lower quality, Google will most likely ignore it to leave the storage space available for higher-quality content. And we can expect the quality standards to get only stricter in the future.
STEP 2: Monitor your index coverage
A URL can suffer from the “Crawled ‐ currently not indexed” status because it was indexed in the past, but Google decided to deindex it over time.
If you wonder why, it likely is:

The solution to deindexed pages is closely related to their quality. You should always ensure your page serves the best quality content and is up to ****.
Don’t assume that once a page is indexed, you don’t need to do anything with it again because Google can change the way it evaluates your content over time.
For example, it’s possible for a page to be indexed without content. However, as bots recrawl the page, then Google may consider it “Crawled, currently not indexed,” despite the signals that were previously seen as crucial.
To monitor your index coverage easily, use ZipTie ‒ the technical SEO and indexing intelligence platform. ZipTie lets you monitor indexing delays and updates you weekly on the amount of content that got deindexed.
Keep monitoring your pages and implement changes and improvements if necessary. After fixing the issues, you can submit the analyzed URLs to Google Search Console to help Google notice the changes quicker.
STEP 3: Design a sound website structure
Good website architecture is key to helping you maximize the chances of getting indexed. It allows search engine bots to discover your content and better understand the relation between pages.
That’s why it’s crucial to provide a good website architecture and ensure there are internal links to the page you want to be indexed.
Let’s imagine a situation where you have a good-quality page, but the only way Google found it is because you put it in your sitemap.
Google might look at the page and crawl it, but since there are no internal links, it would assume the page has less value than other pages. There’s no semantic or structural information to help it evaluate the page. That might be one of the reasons why Google decided to focus on other pages and leave this one out of the index after crawling it.
To learn more about website structure, check out our article on How To Build A Website That Ranks And Converts.
STEP 4: Limit your duplicate content
First and foremost, you should ensure you create original pages. Google wants to present unique and valuable content to users. That’s why, when it realizes during crawling that some pages are identical or nearly identical, it might index only one of them.
Unfortunately, duplicate content might be unavoidable (e.g., you have a mobile and desktop version). You don’t have much control over what appears in search results, but you can give Google some hints about the original version.
If you notice a lot of duplicate content indexed, evaluate the following elements:
- Canonical tags: these HTML tags tell search engines which versions are the original ones.
- Internal links: ensure internal links are pointing to your original content. Google might use it as an indicator of which page is more important.
- XML Sitemaps: ensure only the canonical version is in your sitemap.
But remember that these are only hints, and Google is not obligated to follow them.
If Google ignores your canonical tag, you can spot it thanks to the “Duplicate, Google chose different canonical than user” status in GSC.
For example, Adam Gent, an SEO freelancer, shared an interesting case with the SEO community. His page was reported as “Crawled ‐ currently not indexed” because Google thought it was a duplicate page.
It’s not entirely clear why Google might choose “Crawled – Currently Not Indexed” over a dedicated status for duplicate content. One of the possible explanations is that the status will change later after Google decides if there’s a more suitable one for the page.
Another option might be a reporting bug. Google might simply make a mistake while assigning the statuses. Unfortunately, the situation is more challenging because “Crawled – Currently Not Indexed” doesn’t give you as much information as a dedicated status for duplicate content.
How to check if a duplicate page is showing in the search results? Head to our article on How To Optimize Duplicate Content for SEO.
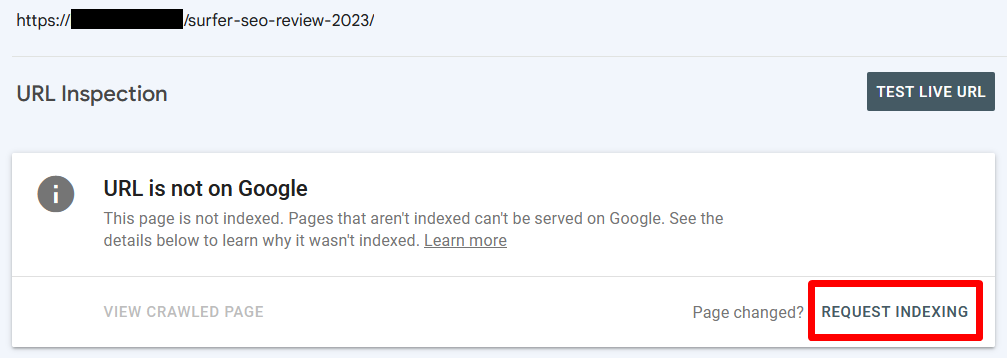
STEP 5: Manually submit a request to Google to re-crawl your specific URLs.
Before manually submitting a request to Google, take care of your website content and do it all to maximize your authority. Next, go to URL inspection, enter the URL address, and hit Request Indexing.
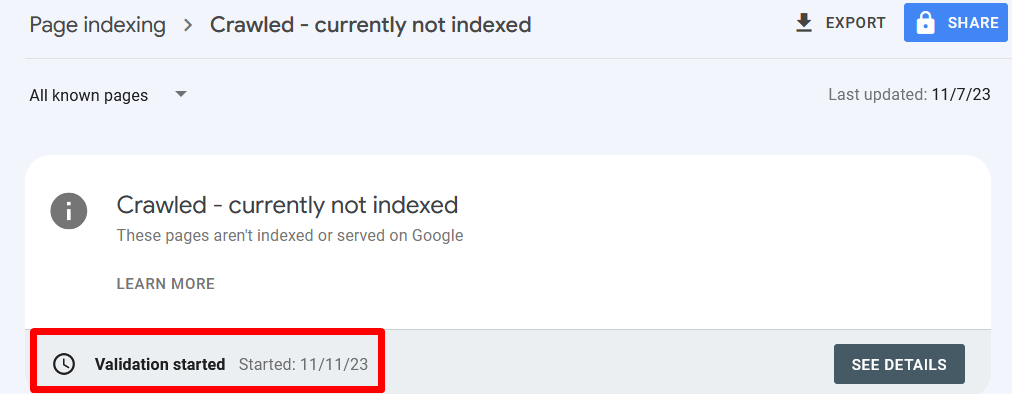
You can also try a second, more automatic way. Go to Indexing → Pages → “Crawled – Currently Not Indexed”. Choose All known pages, and hit Validate Fix.
Once Google accepts your request, you’ll see when validation has started.
Other reasons for “Crawled – Currently Not Indexed”
When completing 5 main steps from our article, you should wait a minimum of a few days for Google to reindex the given pages. After one or two weeks, check your website in Google Search Console again, and enjoy your solved problem!
But…
If you still face “Crawled – Currently Not Indexed,” we have your last lifelines!
Your Domain Rating (DR) is too little.
By producing a lot of high-quality content for your website, you can get more trust from Google and boost your domain authority. It looks simple. However, you should know that you cannot beat the competitors and have a high indexing level without backlinks.
*** to start getting natural and relevant backlinks?
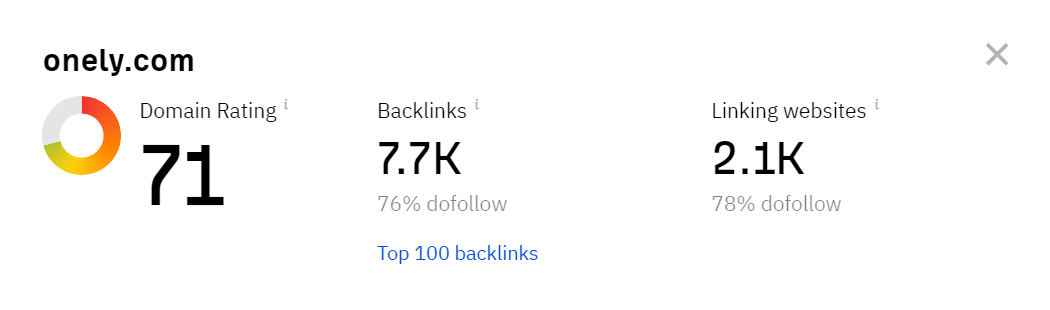
- Check your website’s Domain Rating in Ahrefs’ DR Checker (it’s your starting point),
- Start with one quality backlink weekly (from guest posting),
- Find out additional passive backlinks methods (like creating viral content, preparing worthy infographics, and sharing your own industry statistics).
Regularly acquiring backlinks will convince Google that your website is valuable, resulting in a higher indexing status and better Domain Rating.
You don’t have a temporary sitemap.xml
Sometimes, the destination URLs of redirects appear in the “Crawled – Currently Not Indexed” report. This isn’t due to incorrect redirects but rather relates to how frequently Google crawls your website. It’s possible to notice that Google crawls these destination URLs but doesn’t add them to its index.
A potential solution involves creating a temporary sitemap.xml file. Begin by extracting all URLs from the “Crawled – Currently Not Indexed” report and align them with established redirects using Excel or Google Sheets.
Then, generate a sitemap, which can be done with tools like XML Sitemaps, and upload it to your Google Search Console dashboard.
You need a technical SEO help
Still having the same problem? We can help you fix “Crawled – Currently Not Indexed”. Here’s what you can do now:
- Contact us,
- Receive a personalized plan from us to deal with your indexing issues,
- Enjoy your content in Google’s index!
Still unsure of dropping us a line? Read how technical SEO services can help you improve your website.
“Crawled – Currently not indexed” vs. “Discovered – currently not indexed”
The “Crawled – Currently Not Indexed” status is commonly confused with another indexing issue in the Index Coverage (Page indexing) report: “Discovered – currently not indexed.”
Both of the statuses indicate that the page is not indexed. However, in the case of “Crawled – Currently Not Indexed,” Google has already visited the page. Meanwhile, in “Discovered – currently not indexed,” the URL is known to Google, but it wasn’t crawled yet for some reason.

Some of the reasons for these statuses might be similar, including poor-quality pages and internal linking structure problems. However, when you see a “Discovered – currently not indexed” status, you need to additionally investigate why Google couldn’t or didn’t want to access the page. For example, it might indicate problems with the overall quality of the whole website, crawl budget issues, or server overload.
Wrapping up
“Crawled – Currently Not Indexed” is mainly associated with page quality, but in reality, it can indicate many more problems, like confusing website architecture or duplicate content.
Here are the key takeaways that can help you deal with the “Crawled – Currently Not Indexed” status:
- Add unique and valuable content to your pages. Once you have done it, submit those URLs to the Google Search Console. This way, Google may notice changes quickly;
- Review your website architecture and ensure there are internal links to your valuable pages;
- Decide which pages should and shouldn’t be indexed to help Google prioritize the most valuable URLs;
- Get high-quality, natural, contextual backlinks (external links) to skyrocket your Domain Rating (DR);
- Implement temporary sitemap.xml (is useful in solving the problem of target URLs from 301 redirects that have been indexed by Google but aren’t yet in the index).
If you need help addressing the “Crawled – currently not indexed” status on your website, our technical SEO services are what you’re looking for.
“Crawled – Currently Not Indexed” – FAQs
What are the most common questions and answers about “Crawled – Currently Not Indexed”
No worry. It’s normal – Google doesn’t index RSS feeds because their primary purpose is distributing content to RSS readers, not to be displayed directly in search results. RSS feeds typically contain condensed or streamlined versions of content intended for quick transmission of updates rather than full indexing by search engines.
2. Are Google Index URLs with redirects?
John Mueller, a representative of Google, made a statement on Twitter clarifying that Google’s indexing process doesn’t include pages set up with redirects. Pages with redirects are categorized differently and shouldn’t be confused with pages marked as “Crawled – Currently Not Indexed”.

![YMYL Websites: SEO & EEAT Tips [Lumar Podcast]](https://www.lumar.io/wp-content/uploads/2024/11/thumb-Lumar-HFD-Podcast-Episode-6-YMYL-Websites-SEO-EEAT-blue-1024x503.png "YMYL Websites: SEO & EEAT Tips [Lumar Podcast]")

