
Posted by
Shay Harel
Recently a portion of Yandex’s source code was leaked.
What does that mean to your SEO moving forward?
Think about this…
Understanding their source code will give you a glimpse into the inner workings of the search engine. This gives you an opportunity to analyze the Yandex ranking factors and compare them to those used by Google.
While Google is known for its complex and rich data, it’s worth noting that Yandex still holds a significant market share in certain regions, particularly in Russia. The Yandex source code leak is a valuable opportunity for the SEO community to understand how Yandex scores and ranks pages.
In this post, I’ll break down some of the high-level themes we see as well as show you some unique elements of the algorithms that might change how you do SEO moving forward.
But first, let’s explore why analyzing the Yandex algorithms is so important.
Why Look at Yandex?
The Yandex leak has given us the first-ever opportunity to see the actual source code of a major search engine. As you know, Google has always given general advice that doesn’t reveal the specifics of the search engine.
This means we have always relied on user testing to understand how to make our content more visible in the search results.
Now, for the first time, we can see some of the inner workings of Yandex’s search algorithm, including details about the ranking factors used to determine the relevance and authority of a webpage. This has provided valuable insight into the ways in which Yandex looks at search ranking.
Yandex’s source code has brought to light some significant scoring systems used by the Yandex search engine. This begs the question. Can we assume that Google uses similar ranking factors?
Upon analysis, it’s clear that Yandex’s list of ranking factors is significantly smaller than what we would expect from Google. However, this doesn’t mean that the factors used by Yandex are any less important.
In fact, up until now, the SEO community might not have been aware of many of the factors we are seeing in Yandex. This means understanding these factors might give you an SEO advantage moving forward.
You might have a golden opportunity to re-evaluate your optimization strategies and potentially discover new ways of improving page rankings.
Now, before I’m accused of spreading misinformation, I’m not saying that Google uses any of these ranking factors. I’m just asking the question.
Also, it’s worth noting that this leak may also provide new opportunities for spammers to exploit these systems. As SEO professionals, it’s important to stay vigilant and continue to focus on ethical optimization techniques.
User Behavior
It is very interesting to see the emphasis Yandex places on user behavior. According to the leaked source code, Yandex heavily considers metrics such as click-through rate (CTR) and dwell time when determining the relevance and authority of a webpage. There are 150 ranking factors around this (approx. 8% of all factors).
Also, there are many factors that sound strikingly similar to what Google has been advocating for years. What I’m referring to is placing emphasis on traditional SEO factors such as backlinks and keyword usage.
There are hundreds of factors that directly or indirectly use PageRank which is a system that ranks web pages based on the number and quality of links pointing to them (Google who invented PageRank, was the first search engine to measure and score pages based on it.)
The implications of this leak are significant for SEO professionals looking to optimize their content for Yandex.
Overall, the leak of Yandex’s source code provides valuable insights into the inner workings of a major search engine and offers new opportunities to improve your optimization strategies.
Analysis & Stats
Let’s talk about numbers and drop a few metrics. We have to as marketers. 😉
There are 1922 ranking factors, you can find them all here.
The ranking factors are grouped together. Below is a chart showing the top groups.
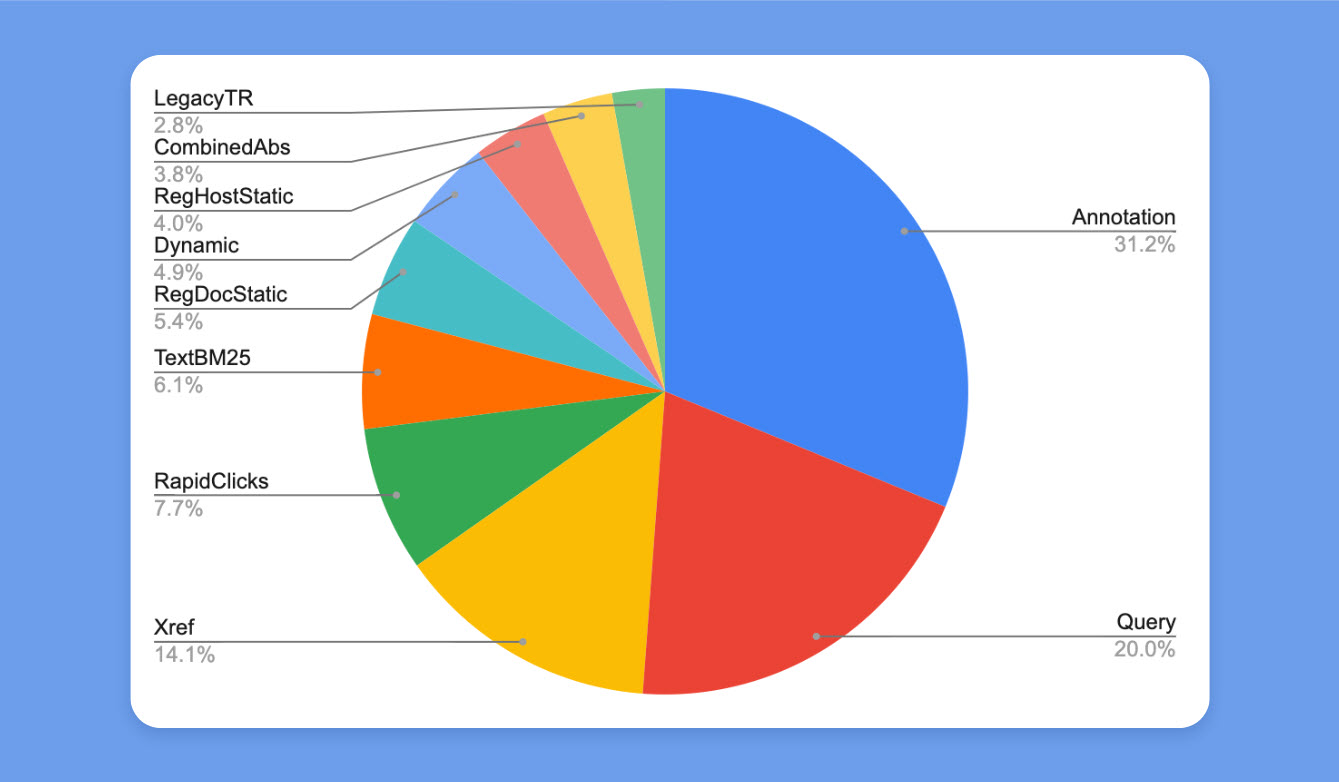
Okay, let’s get into some of the ranking factors.
Yandex Ranking Factors
Digging into the information, I can identify two obvious themes worth noting:
Annotation
From what I see, many of the factors are grouped together. One of the leading groups is called Annotation. This group includes things like UX, CTR, bounce rate, and dwell time.
From what I see, annotation is a leading factor that includes the semantic analysis of page score and CTR predictions. What’s more, it seems like there might be an Annotation index. We can see that they’re using more than just one semantic weighted factor. You can find the classic Weighted BM15, among proprietary weighted schemas that they seem to use.
Simply put, BM25 is an algorithm that measures documents in the search engine’s index and measures how relevant they are to a user’s search query. It’s a bag of words model that measures the words in a document but disregards the grammar and word order, and focuses on how frequently words appear in the document.
Query Factors
Second in line are Query factors. These factors seem to be the more common and simple factors such as:
- Wordcount (Factor #59) where you can see the actual formula used: Min(number of query words/10, 1.f) – Please don’t start spamming pages accordingly. 😉
- Inverted wordcount (Factor #60): shows a simple formula of “1 / number_of_words_in_query”.
- IDF (Inverse Document Frequency): This is a measure used in natural language processing and information retrieval to reflect the importance of a term in a collection or corpus of documents. Most SEOs should be familiar with it as some tools utilize it in reports such as the Rank Ranger TF-IDF report.
- Something very interesting here is to see that they categorize and take into account whether the query is a NightQuery or a MorningQuery, and also at specific hours.
Now, there is a lot more to view here. I’m merely looking at annotation and query factors in order to keep this post as short as possible.
Here is a brief summary of the key ranking factors.
Ranking Factor Summary
- PageRank remains a factor in SEO
- Backlinks are crucial
- CTR (click-through rate) and bounce rate are major factors
- Frequent site audits to address 404/5xx errors are crucial for optimizing SEO
- On-page factors continue to play a role in SEO, ranging from basic analysis to more advanced and semantic analysis
- The ranking of pages on the Yandex search engine can be affected by user behavior, including the number of times a URL is added to user bookmarks and the active time spent on a page after clicking on a query from the search engine, as measured by the Yandex bar and browser tools.
- The average domain position across all queries is a ranking factor.
- Crawl depth is a ranking factor.
- If a URL is the last visited in a search session, meaning the user has found what they were looking for.
- Having Google Analytics on the site is a ranking factor. Imagine that…
- UX (user experience) encompasses various factors that assess the quality of user experience on a page, such as broken videos, links, the number of ads, page interactions, and repeat visits, all of which are measured.
Now that we’ve looked at some of the ranking factors from a high level, let’s now look at some of the more unexpected factors.
Looking into these factors will give you a new perspective and hopefully give you some new opportunities to test
New Opportunities: Unexpected Ranking Factors
Yandex’s search algorithm presents multiple elements to study, many of which will likely be exploited by spammers, others offering opportunities to optimize for Google’s search. Here are a few observations that caught my eye.
Factor #63 | Name: HasNoQueryURLShows
The translated description: “There is no clickability information for this url for this request 1 – request or request-url is not in the click base, 0 – request-url is in the click database”
Take this one, what if whether or not your landing page URL got hits on previous searches or not was a ranking factor? If so, you may want to consider pushing for initial clicks to influence this factor.
Factor #850 | Name: BrowserBookmarksUrl
The description of this factor is “The more users add to bookmarks a url, the more factor value it has”.
Really?
At first, it does sound old school, but thinking about it further, the only way for them to measure how users bookmark URLs is on the Yandex Browser or Bar. I wonder if Google does the same with Chrome. We’ll probably see new SEO checklists that include adding pages to favorites 😉.
Factor #243 followed by a series of factors that are based on Clickstream data from the Yandex bar
Here’s a translation of the description of one of the factors: “average active continuous user time (in seconds) on the page after clicking on a query from a search engine. (The factor depends on the pair (query, url)). According to the internal counter of Yandex.Bar / Elements / Browser”
It seems that users who use Yandex.bar to search the web and click on results will affect page rank.
Some Key Takeaways
As you have seen, according to what we are seeing, Yandex features some interesting and unexpected ranking factors.
For instance, Google has said for years that Bounce Rate is a noisy signal and they don’t use click-through rates in ranking content.
Yet it seems that Yandex might be using those signals in ranking content.
Now, as I mentioned above, I’m not making any claims here. But I am asking the question. Do some of these factors affect how Google ranks pages?
Since Google is not likely to share its source code any time soon, the only way to find out is to do a little user testing.
About The Author




