
If you’re involved in SEO or content strategy in any professional capacity, chances are you’re familiar with tools like semrush and ahrefs. And if you’re familiar with tools like those, you’re probably familiar with the wide variety of metrics they provide, or at least a selection of them.
Some are straightforward and ubiquitous—we’re all familiar with search volume and keyword difficulty, and at this point, chances are that your clients are as well. What’s not straightforward, however, is how this data is gathered and if or why you can trust it. Because these two extremely powerful tools have risen to prominence, there hasn’t been much use in questioning them, as unanswered questions will bring about little recourse.
But, it’s important to understand how these metrics are being calculated, the margin of error presented throughout doing so, and the confidence you should have in trusting these numbers or, more importantly, presenting them to clients. At a glance, it seems that being presented with these metrics without any analytics work is a cheat code for reporting. Still, it’s important to understand what they’re actually telling us—and why that isn’t always what we think it is. Estimated traffic is a handy guideline that can tell us a lot about the state of our content, but it is most definitely not an accurate representation of the organic traffic that a page receives.
To understand estimated traffic, we must first understand the underlying principles of the two main determining factors: search volume and keyword difficulty.
How is Search Volume Measured?
In days past, search volume was a straightforward and accurate statistic that you could get directly from Google. We’re talking about days before GDPR and privacy agreements, and things were a little simpler. You could see accurate data in Google Keyword Planner because Google had the data (and remember that it still does), and there was no obvious reason not to share it with you. The more you understood about the demand for whatever you were working on, the more likely you were to be successful in the execution of its campaign, and the more likely you were to return and spend more dollars on ads.
The problem was when SEOs got the hang of wrangling this data. They could now clearly identify the most lucrative and in-demand topics and skew all of their efforts toward dominating SERPs for those items or concepts. This means that effectively, whatever query in a big list of semantically related concepts was listed as having the highest search volume, you could be more or less sure that that would be targeted relentlessly by marketers. So, Google decided to obscure that information, which they do now largely through clustering and bucketing.
What about Keyword Difficulty?
In the old days, before the prevalence of paid third-party tools, “keyword difficulty” was not a unified statistic by any means. However, there’s always been one equation (with some variation, of course) that could be used to determine—or better said, to get a rough idea of—the competitive difficulty of a keyword and how hard it would be to rank.
This formula involves:
- The quality/authority of the pages already ranking
- The backlink profiles of those same pages
- The search intent of the query itself, and
- The total number of pages currently ranking
It is interesting to note here that by semrush’s own admission (or rather, omission), the number of results is not candidly stated as a factor that’s taken into account when calculating keyword difficulty. That being said, all of the other factors previously mentioned are present in that list.
Keyword difficulty, put simply, is an extremely useful stat. It’s also extremely imaginary.
It’s unlikely that there is a perceptible difference in the effort that it would take to rank for a keyword term with a KD of 87 rather than 83, though if you take these statistics as gospel, you will believe as much. These metrics are not so much a map as they are a compass, they won’t show you exactly where your goal is, but they will point you in the right direction (and sometimes, just as importantly, point you away from the wrong one).
The Good and Bad of Estimated Traffic Share
Now that we’re on the same page about the two factors above, we can examine how they come together to create the sometimes misleading—and often inaccurate—statistics of estimated traffic. Let’s examine a client example, using semrush for this particular example.
Below are the largest estimated drivers of traffic on a page level:
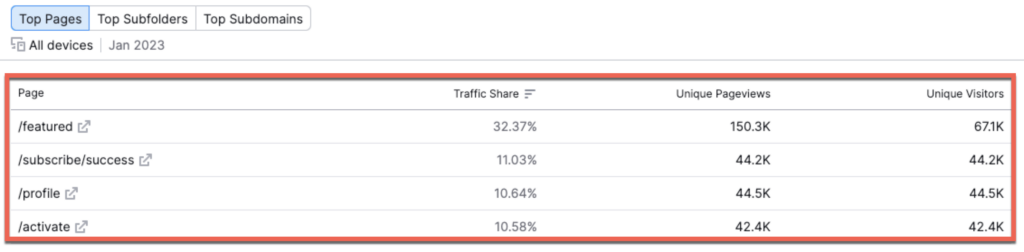
We’re given not only the estimated pageviews of each page (and many others should you continue to scroll) but the overall traffic share of the website as a whole. This means that, according to semrush, the /featured page will account for a whopping one-third of all traffic driven from organic search to the site in a cumulative 150,300 unique pageviews. We see a large dip into the second place position, as the figures pretty much level out in terms of traffic for the next several pages.
Now let’s compare these figures to the actual data gathered from Google Analytics:
First, the good news. The top organic traffic driver, as estimated by semrush, was correctly identified. This is impressive and means that there might just be some method to this madness. That is, unfortunately, all the good there is to see here.
Now, the bad news. Look at those traffic discrepancies—yikes. Semrush estimated close to a 10x higher unique pageview count from the period of January (the most recent complete month) than what was actually recorded by Google Analytics. Additionally, the estimated traffic share was almost exactly 2x higher as compared to what actually happened.
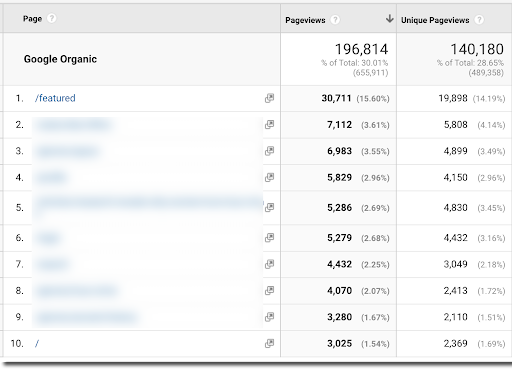
This is problematic for a few reasons. The first is that many clients have subscriptions to these tools and monitor them with some degree of regularity. It is going to be a deflating reporting call if you crush them with the news that, despite what they’ve been told, a page is actually only generating 15% of the pageviews that they’ve been told to expect by other sources. Of course, if a client is monitoring third-party tools and not a reporting dashboard, that’s really out of our control—but it doesn’t mean they won’t be disappointed or surprised.
The second reason is that this means that according to all of the factors that semrush measured in this instance, human behavior has actually differed greatly from what it should have been on paper. Go figure.
So, How is Estimated Traffic Share Actually Calculated?
Well, the answer is relatively complicated in nature but can be understood rather straightforwardly. A basic summary of the breakdown is as follows:
First, semrush took inventory of all the keyword rankings for every page of the client’s site that it has on file and noted their last known ranking position. Then, it estimated a clickthrough rate based on the percentage that it algorithmically finds likely for a query within that vertical.
As an example, if the client site ranked #4 for a certain keyword, semrush would calculate that the site would receive an assigned percentage of the total search volume registered for that keyword.
You can see that through each step of this process of estimation, the calculation becomes more estimated than known and, therefore, more tenuous as a whole. It’s like a game of telephone with data, in which the person who started the game was guessing in the first place.
So the calculation probably looks something like this:
[Estimated Search Volume] x [Estimated Clickthrough Rate] = [Estimated Traffic]
Let’s look at an example scenario:
| Keyword total monthly search volume | 1,700 |
| Current ranking position of keyword | #4 |
| Estimated clickthrough rate based on position | 13% |
1,700 x .13 = 221
Total estimated monthly traffic for example keyword = 221
This example is then replicated over and over for every keyword ranking that the page possesses according to whatever tool you’re using. While 221 pageviews is a relatively low number by itself, once this calculation is applied for over a thousand keywords, the sum of estimated traffic can quickly get out of hand and detached from reality.
Estimated traffic is not, in fact, estimated traffic. It’s more realistically projected traffic according to the current status and rankings of a website’s associated keywords. It is not going to give you accurate traffic information—far from it—but it can be used as a divining rod to understand the state of your keywords and their resulting organic traffic. Think of it more as a rough temperature check on how your content is performing rather than an exact measurement.
Estimated traffic share is not an inherently bad number to look at; we just need to understand its limitations and use it accordingly.
But Wait, The Data is Still Useful
One of the best ways to use estimated traffic to our advantage is to check if there is a disconnect between estimated traffic share and a site’s Google Analytics data. This information can be a helpful way to identify upcoming trends or possible issues that need attention.
For example, if a page is performing great in estimated traffic but poorly in GA data, there are a couple of potential insights we can gather:
Potential Insight #1: The page is increasing in strength, and traffic will increase soon (though not likely to the level projected by third-party tools)
It’s not uncommon to see third-party tools catch onto trends before they’re reflected in analytics data. If you make optimizations to a piece of content, tools will often catch the spike in rankings (from page eight to page three, for instance) and reflect that in the estimated traffic data. In reality, moving up from page eight to page three will still leave you with close to zero organic traffic, but if the trend continues, your GA data will reflect it eventually.
Potential Insight #2: The content is underperforming in terms of CTR
If a page has strong rankings and high estimated traffic but still gets a low share of the site’s organic acquisition, you might have a problem with SERP appearance. Seeing a high estimated traffic (or traffic share) for a URL that just isn’t performing well can be an indicator that meta titles and descriptions need to be rewritten to appear more appropriate for related queries in SERPs.
Potential Insight #3: The page is ranking for a lot of unqualified traffic
If a page has high estimated traffic but isn’t actually performing well, examine the keywords it’s ranking for. If many keywords aren’t appropriate for the search intent that would lead to the page in organic search, people aren’t going to click through. This is a good opportunity to evaluate the content of the page and potentially rewrite aspects of it to omit the unwanted keywords and replace them with something more appropriate to the page that has a higher likelihood of driving traffic.
Conclusion
Traffic estimated by third-party tools is, at best, usually inaccurate. At worst, it’s a complete misunderstanding of the way human behavior affects organic search performance and a mischaracterization of the way the various factors above culminate. But within its core is a helpful statistic that can be taken as a thermometer check of your content’s performance, give insights as to how and why it’s working, and do the same for what’s not. Just don’t take it as fact.



