
Google is placing more importance on the content source, specifically the author, when ranking search results. The introduction of Perspectives, About this result and About this author in the SERPs makes this clear.
This article explores how Google can potentially evaluate content pieces through their authors’ experience, expertise, authoritativeness and trustworthiness (E-E-A-T).
E-E-A-T: Google’s quality offensive
Google has highlighted the significance of the E-E-A-T concept for improving the quality of search results and on-SERP user experience.
On-page factors such as the general quality of the content, link signals (i.e., PageRank and anchor texts), and entity-level signals all play a vital role.
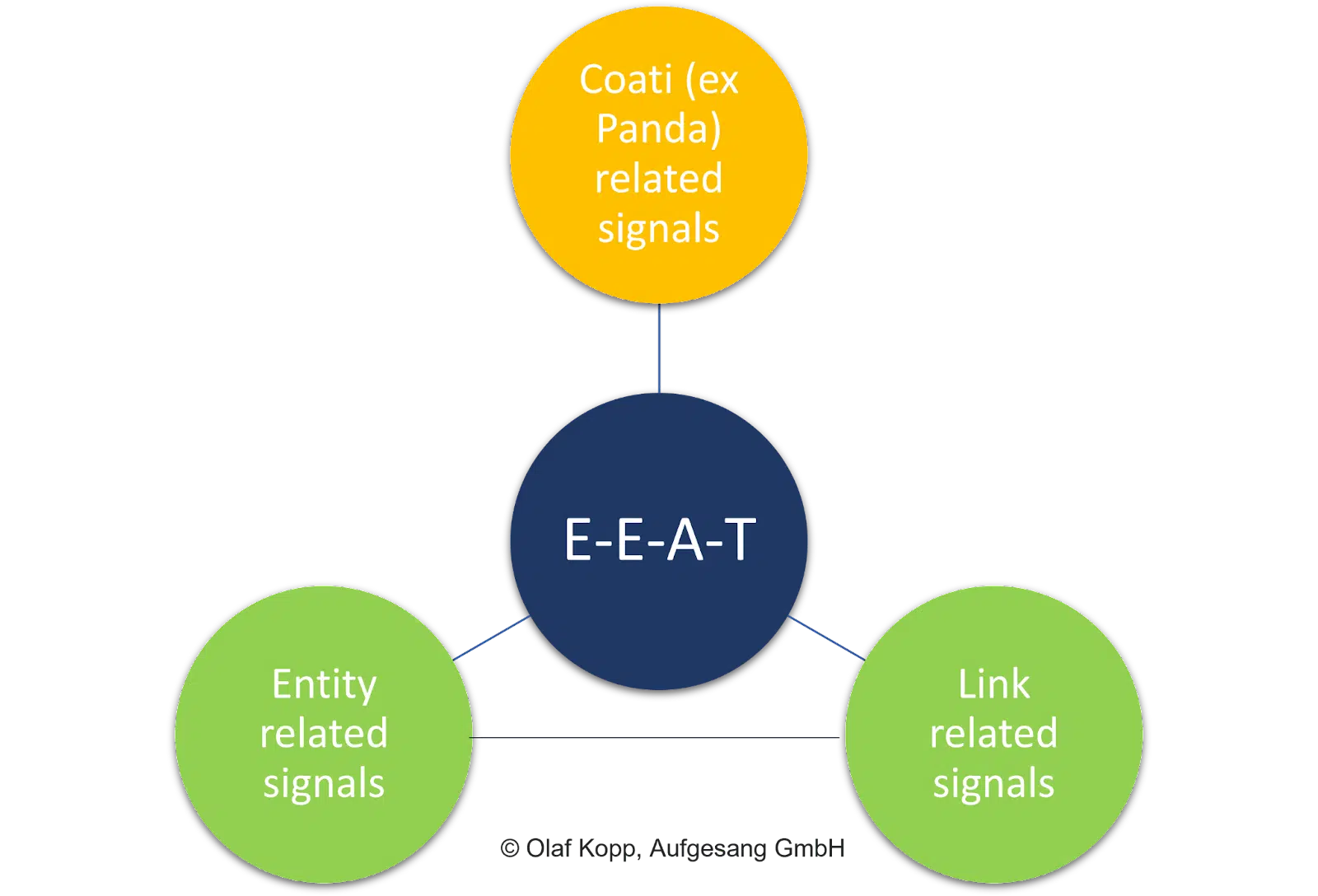
In contrast to document scoring, evaluating individual content is not the focus of E-E-A-T.
The concept has a thematic reference related to the domain and originator entity. It is independent of the search intent and the individual content itself.
Ultimately, E-E-A-T is an influencing factor independent of search queries.
E-E-A-T mainly refers to thematic areas and is understood as an evaluation layer that assesses collections of content and off-page signals in relation to entities such as companies, organizations, people and their domains.

The importance of the author as the source of content
Long before (E-)E-A-T, Google tried to include the rating of content sources in search rankings. For instance, the Vince update from 2009 gave brand-created content a ranking advantage.
Through projects like Knol or Google+, which have long since ended, Google has tried to collect signals for author ratings (i.e., via a social graph and user ratings).
In the last 20 years, several Google patents have directly or indirectly referred to content platforms such as Knol and social networks such as Google+.
Evaluating the origin or author of a content piece according to the E-E-A-T criteria is a crucial step to developing the quality of search results further.
With the abundance of AI-generated content and classic spam, it makes no sense for Google to include inferior content in the search index.
The more content it indexes and has to process during information retrieval, the more computing power is required.
E-E-A-T can help Google rank based on entity, domain and author level applied on a broader scale without having to crawl every piece of content.
At this macro level, content can be classified according to the originator entity and allocated with more or less crawl budget. Google can also use this method to exclude entire content groups from indexing.
How can Google identify authors and attribute content?
Authors belong to the person entity type. A distinction must be made between already known entities recorded in the Knowledge Graph and previously unknown or non-validated entities recorded in a knowledge repository such as the Knowledge Vault.
Even if entities are not yet captured in the Knowledge Graph, Google can recognize and extract entities from unstructured content using machine learning and language ******. The solution is named entity recognition (NER), a subtask of natural language processing.
NER recognizes entities based on linguistic patterns and entity types are assigned. Generally speaking, nouns are (named) entities.
Modern information retrieval systems use word embedding (Word2Vec) for this.
A vector of numbers represents each word of a text or paragraph of text, and entities can be represented as node vectors or entity embeddings (Node2Vec/Entity2Vec).
Words are assigned to a grammatical class (noun, verb, prepositions, etc.) via part-of-speech (POS) tagging.
Nouns are usually entities. Subjects are the main entities, and objects are the secondary entities. Verbs and prepositions can relate the entities to each other.
In the example below, “olaf kopp”, “head of seo”, “co founder”, and “aufgesang” are the named entities. (NN = noun).
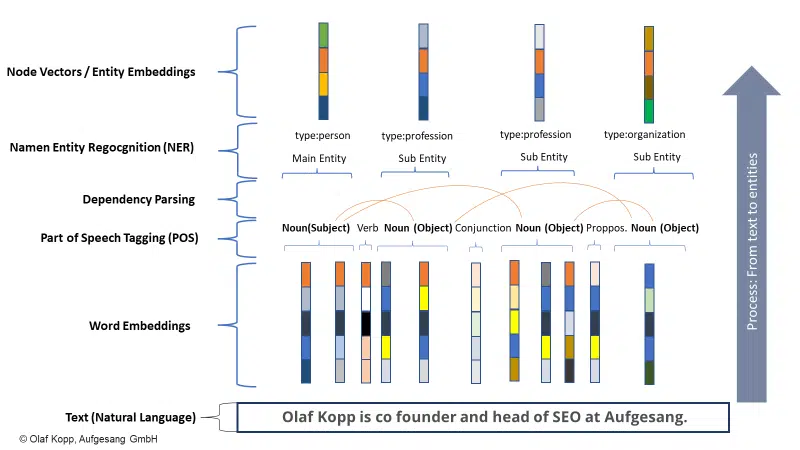
Natural language processing can identify entities and determine the relationship between them.
This creates a semantic space that better captures and understands the concept of an entity.
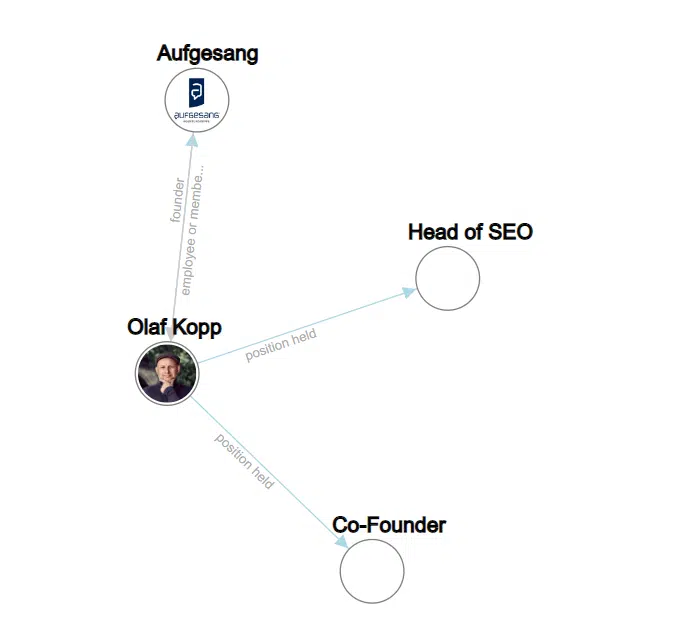
You can find more about this in “How Google uses NLP to better understand search queries, content.”
The counterpart to author embeddings is document embeddings. Document embeddings are compared with author vectors via vector space analysis. (You can learn more in the Google patent “Generating vector representations of documents.”)
All types of content can be represented as vectors, which allows:
- Content vectors and author vectors to be compared in vector spaces.
- Documents to be clustered according to similarity.
- Authors to be assigned.
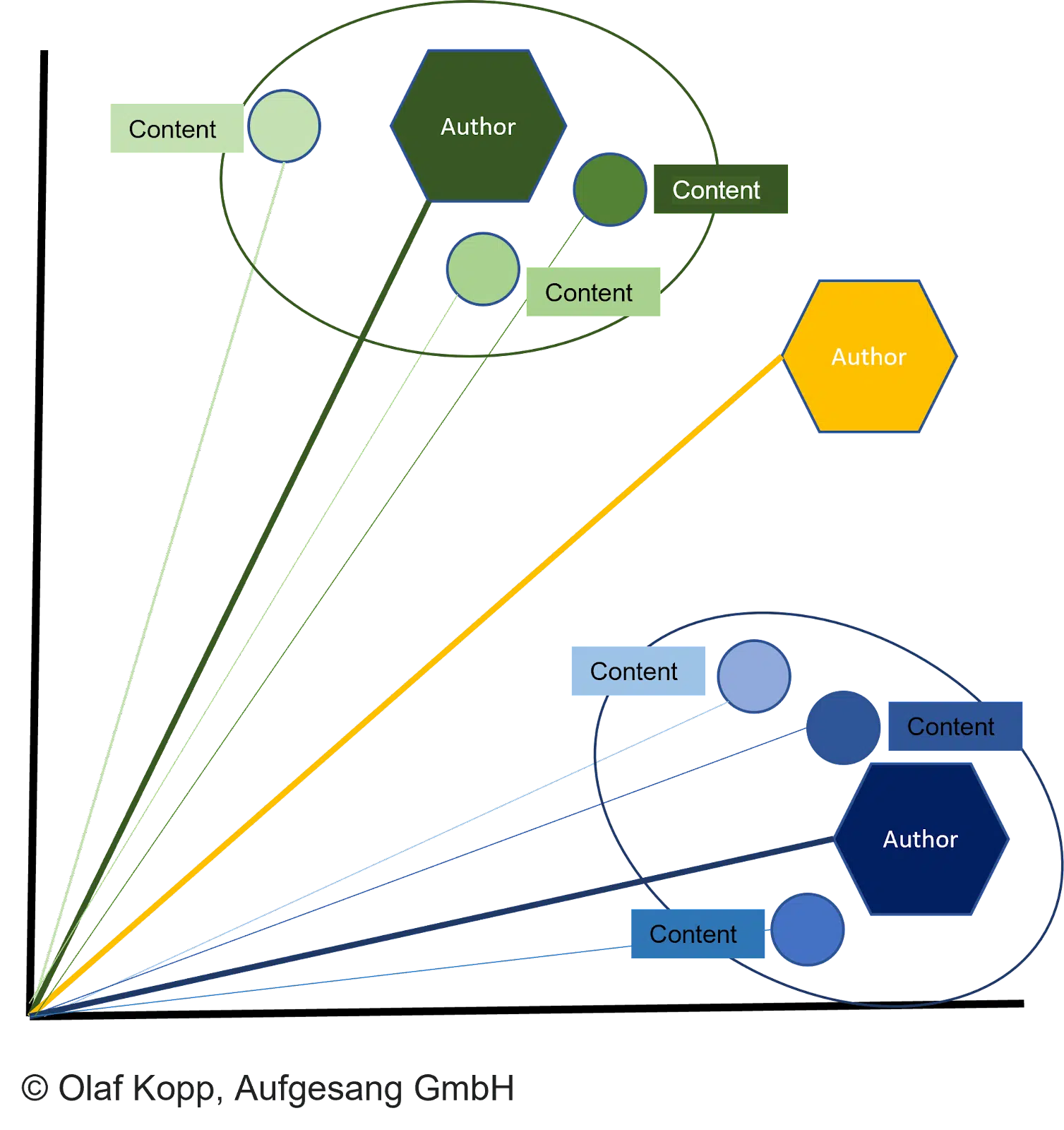
The distance between the document vectors and the corresponding author vector describes the probability that the author created the documents.
The document is attributed to the author if the distance is smaller than other vectors and a certain threshold is reached.
This can also prevent a document from being created under a false flag. The author vector can then be assigned to an author entity, as already described, using the author name specified in the content.
Important sources of information about authors include:
- Wikipedia Articles about the person.
- Author profiles.
- Speaker profiles.
- Social media profiles.
If you Google the name of an entity type person, you will find Wikipedia entries, profiles of the author and URLs of domains that are directly connected to the author in the first 20 search results.
In mobile SERPs, you can see which sources Google establishes a direct relationship with the person entity.
Google recognized all results above the icons for the social media profiles as sources with a direct reference to the entity.
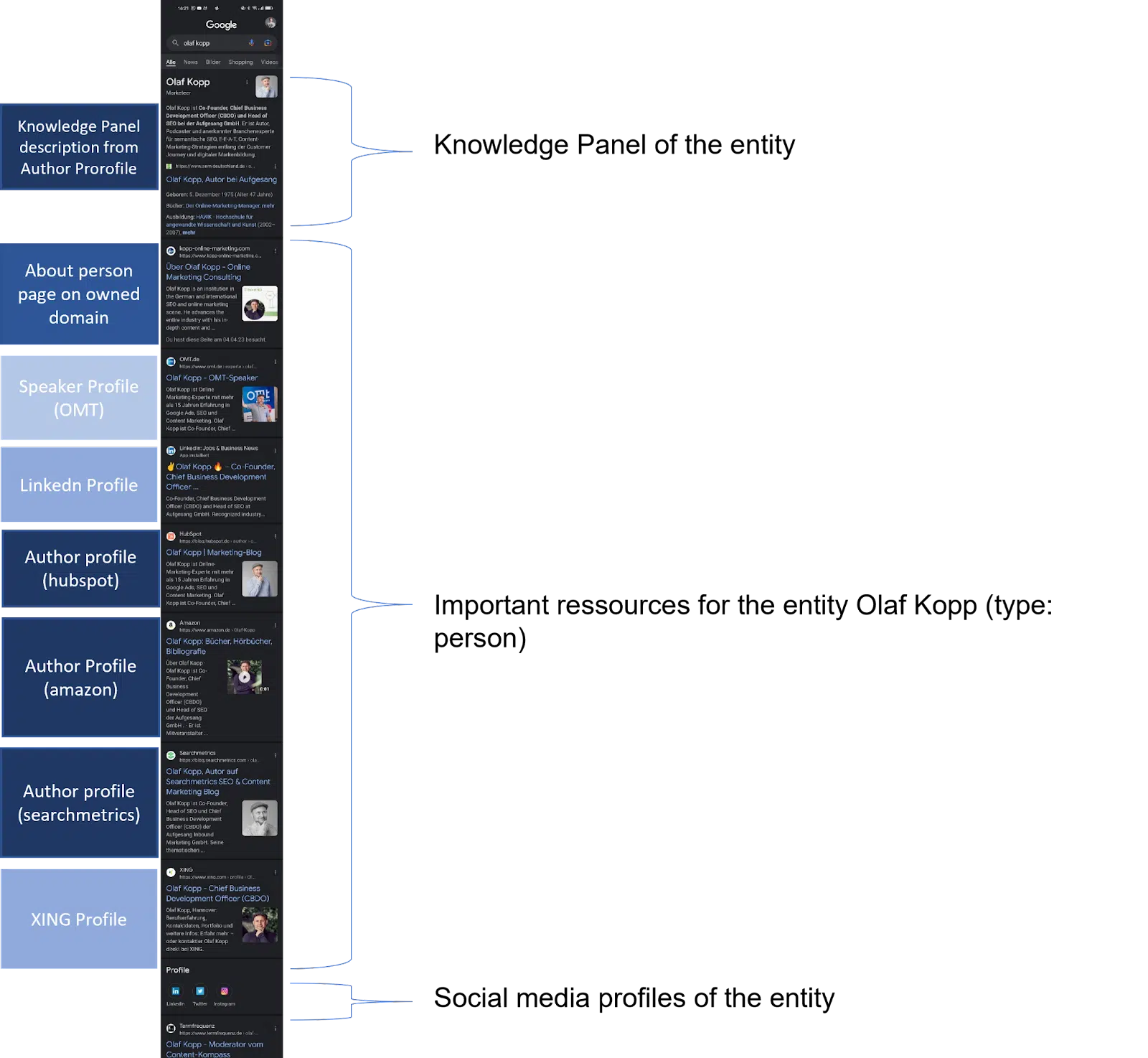
This screenshot of the search query for “olaf kopp” shows that entities are linked to sources.
It also displays a new variant of a knowledge panel. It seems I’ve become part of a beta test here.
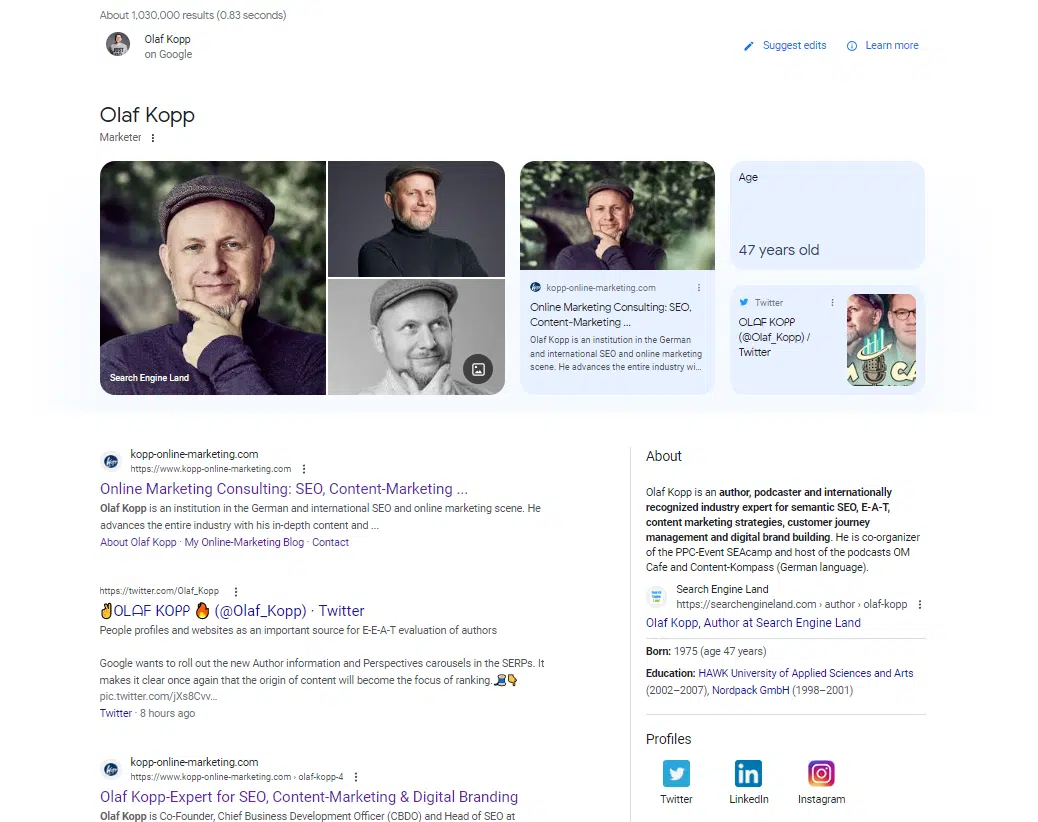
In this screenshot, you’ll see that in addition to images and attributes (age), Google has directly linked my domain and social media profile to my entity and delivers them in the knowledge panel.
Since there is no Wikipedia article about me, the About description is delivered from the author profile at Search Engine Land in the USA and the author profile of the agency website in Germany.
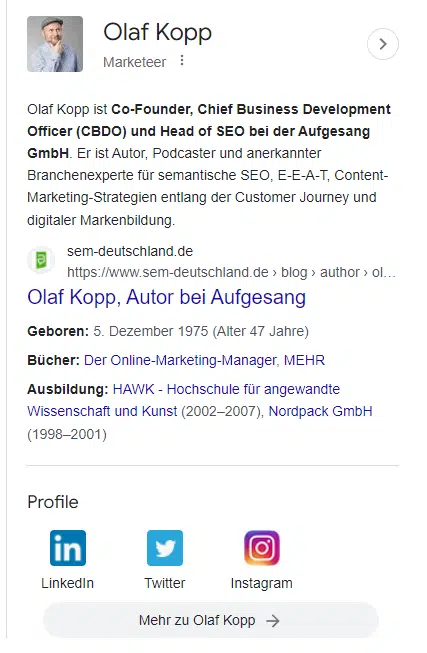
Personal profiles on the web help Google to contextualize authors and identify social media profiles and domains associated with an author.
Author boxes or author collections in author profiles help Google assign content to authors. The author’s name is insufficient as an identifier since ambiguities can arise.
You should pay attention to everyone’s author descriptions to ensure consistency. Google can use them to check the validity of the entity compared to each other.
Get the daily newsletter search marketers rely on.
Interesting Google patents for E-E-A-T rating of authors
The following patents share a glimpse into possible methodologies of how Google identifies authors, assigns content to it and evaluates it in terms of E-E-A-T.
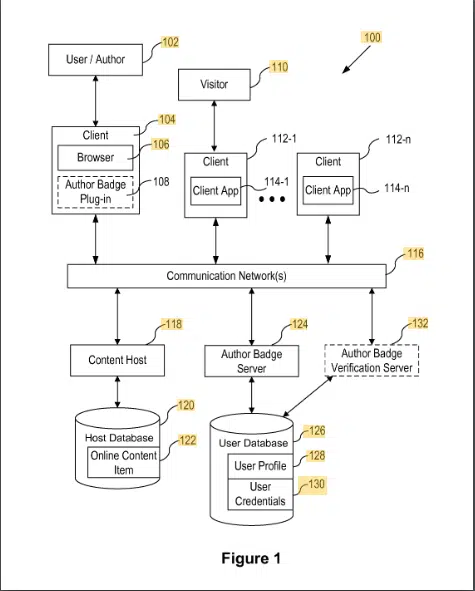
Content Author Badges
This patent describes how content is assigned to authors via a badge.
The content is assigned to an author badge using an ID such as the email address or author’s name. The verification is done via an addon in the author’s browser.
Generating author vectors
Google signed this patent in 2016, with a term up to 2036. However, there have only been patent applications for the USA, which suggests that it is not yet used in Google searches worldwide.
The patent describes how authors are represented as vectors based on training data.
A vector becomes unique parameters identified based on the author’s typical writing style and choice of words.
This way, content not previously attributed to the author can be assigned to them, or similar authors can be grouped into clusters.
Content ranking can then be adjusted for one or more authors based on the user behavior of the user in the past in the search (on Discover, for instance).
Thus, content from authors who have already been discovered and those from similar authors would rank better.
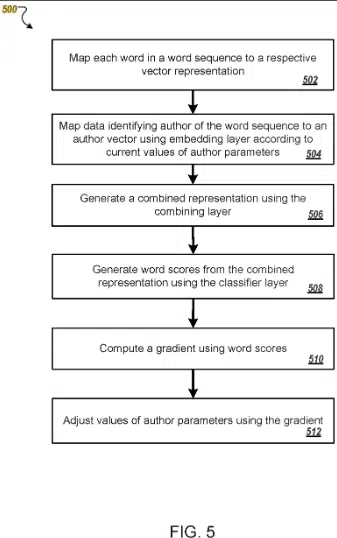
This patent is based on so-called embeddings, such as authors and word embeddings.
Today, embeddings are the technological standard in deep learning and natural language processing.
Therefore, it is obvious that Google such methods will also be used for author recognition and attribution.
Reputation scoring of an author
This patent was first signed by Google in 2008 and has a minimum term of 2029. This patent originally refers to the long-closed Google Knol project.
Thus, it’s all the more exciting why Google drew it again in 2017 under the new title Monetization of online content. Knol was shut down by Google back in 2012.
The patent is about determining a reputation score. The following factors can be taken into account for this:
- Level of frame of the author.
- Publications in renowned media.
- Number of publications.
- Age of recent releases.
- How long the author has been officially working as an author.
- Number of links generated by the author’s content.
An author can have multiple reputation scores per topic and have several aliases per subject area.
Many of the points made in the patent relate to a closed platform like Knol. Therefore, this patent should suffice at this point.
Agent rank
This Google patent was first signed in 2005 and has a minimum term until 2026.
In addition to the USA, it was also registered in Spain, Canada and worldwide, making it likely to be used in Google search.
The patent describes how digital content is assigned to an agent (publisher and/or author). This content is ranked based on an agent rank, among other things.
The Agent Rank is independent of the search intent of the search query and is determined on the basis of the documents assigned to the agent and their backlinks.
The Agent Rank refers exclusively to one search query, search query cluster or entire subject areas.
“The agent ranks can optionally also be calculated relative to search terms or categories of search terms. For example, search terms (or structured collections of search terms, i.e., queries) can be classified into topics, e.g., sports or medical specialties, and an agent can have a different rank with respect to each topic.”
Credibility of an author of online content
This Google patent was first signed in 2008 and has a minimum term of 2029, and has only been registered in the USA so far.
Justin Lawyer developed it in the same way as the Patent Reputation Score of an author and is directly related to use in searches.
In the patent, one finds similar points as in the abovementioned patent.
For me, it is the most exciting patent for evaluating authors in terms of trust and authority.
This patent references various factors that can be used to algorithmically determine an author’s credibility.
It describes how a search engine can rank documents under the influence of an author’s credibility factor and reputation score.
An author can have multiple reputation scores depending on how many different topics they publish content on.
An author’s reputation score is independent of the publisher.
Again in this patent, there is a reference to links as a possible factor in an E-E-A-T rating. The number of links to published content can influence an author’s reputation score.
The following possible signals for a reputation score are mentioned:
- How long the author has been producing content in a subject area.
- Awareness of the author.
- Ratings of published content by users.
- If another publisher publishes the author’s content with above-average ratings.
- The amount of content published by the author.
- How long ago the author last published.
- Ratings of previous publications on a similar topic by the author.
Other interesting information about the reputation score from the patent:
- An author can have multiple reputation scores depending on how many different topics they publish content on.
- An author’s reputation score is independent of the publisher.
- Reputation score may be downgraded if duplicate content or excerpts are published multiple times.
- The number of links to the published content can influence the reputation score.
Furthermore, the patent addresses a credibility factor for authors. The following influencing factors are mentioned:
- Verified information about the profession or the role of the author in a company. It also considers the credibility of the company.
- Relevance of occupation to the topics of the published content.
- Level of education and training of the author.
- Author’s experience based on time. The longer an author has been publishing on a topic, the more credible he is. The experience of the author/publisher can be determined algorithmically for Google via the **** of the first publication in a subject area.
- The number of content published on a topic. If an author publishes many articles on a topic, it can be assumed that he is an expert and has a certain credibility.
- Elapsed time to last release. The longer it has been since an author last published on a topic, the more a possible reputation score for this topic decreases. The more up-to-**** the content is, the higher it is.
- Mentions of the author/publisher in award and best-of lists.
Systems and methods re-ranking ranked search results
This Google patent was first signed in 2013 and has a minimum term until 2033. It has been registered in the USA and worldwide, which makes it likely that Google will use it.
Among the inventors of the patent is Chung Tin Kwok, who was involved in several E-E-A-T relevant Google patents.
The patent describes how search engines, in addition to the references to the author’s content, can also consider the proportion that he can contribute to a thematic document corpus in an author scoring.
“In some embodiments, the determining the original author score for the respective entity includes: identifying a plurality of portions of content in the index of known content identified as being associated with the respective entity, each portion in the plurality of portions representing a predetermined amount of data in the index of known content; and calculating a percentage of the plurality of the portions that are first instances of the portions of content in the index of known content.”
It describes a re-ranking of search results based on author scoring, including citation scoring. Citation scoring is based on the number of references to an author’s documents.
Another criterion for author scoring is the proportion of content that an author has contributed to a corpus of topic-related documents.
“[W]herein determining the author score for a respective entity includes: determining a citation score for the respective entity, wherein the citation score corresponds to a frequency at which content associated with the respective entity is cited; determining an original author score for the respective entity, wherein the original author score corresponds to a percentage of content associated with the respective entity that is a first instance of the content in an index of known content; and combining the citation score and the original author score using a predetermined function to produce the author score.”
The patent’s purpose is to identify “copycats” and downgrade their content in the rankings, but it can also be used for the general evaluation of authors.
Key factors for rating an author
In addition to the possible factors for an author evaluation listed in the patents above, here are a few more to consider (some of which I have already mentioned in my article “14 ways Google may evaluate E-A-T”).
- Overall quality of the content on a topic: The quality that an author delivers about his content on a topic as a whole, independent of domain and format, can be a factor for E-E-A-T. Signals for this can be user signals, links and other quality signals at the content level.
- PageRank or references to the author’s content.
- Co-occurrences of the author in content (podcasts, videos, websites, PDFs, books) with relevant topics or terms.
- Co-occurrences of the author in search queries with relevant topics or terms.
Applying E-E-A-T to author entities
Machine learning methods make it possible to recognize and map semantic structures from unstructured content on a large scale.
This allows Google to recognize and understand many more entities than previously shown in the Knowledge Graph.
As a result, the source of content plays an increasingly important role. E-E-A-T can be algorithmically applied beyond documents, content and domain.
The concept can also cover the author entities of content (i.e., the authors and organizations responsible for the content).
I think we will see an even more significant impact of E-E-A-T on Google search over the next few years. This factor may even be as important for the ranking as the relevance optimization of individual content.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Source link : Searchengineland.com



