
Google began enforcing its site reputation abuse spam policy on May 7, 2024 after announcing the policy two months earlier (when the March 2024 core update rolled out). At that time, we didn’t know if enforcement would be handled via manual actions, an algorithm update, or a combination of both. It ended up being just manual actions at the time and we are still waiting for the algorithmic part to roll out.
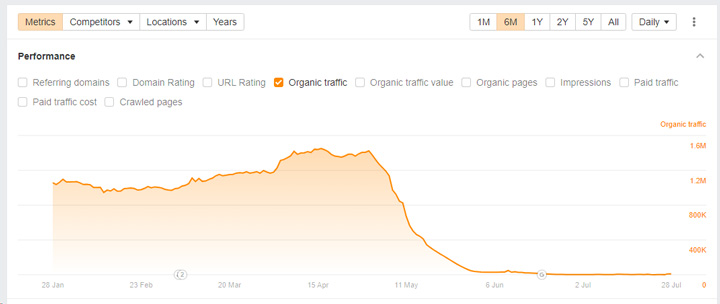
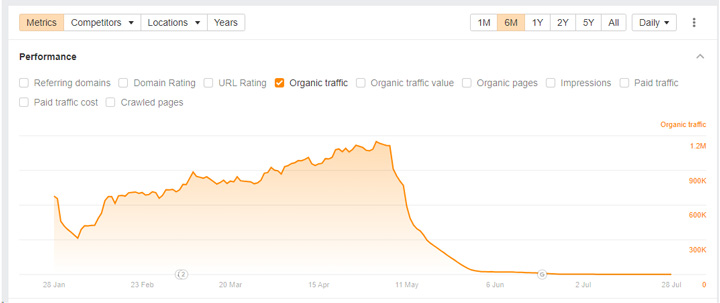
When Google rolled out manual actions for site reputation abuse, many of the sites violating the policy had their content deindexed. That was handled on the directory or subdomain level and search visibility plummeted (for obvious reasons). For example, here are two sites that received manual actions. Note, the drop was just for the directories or subdomains holding the content that violated the site reputation abuse policy and not for the entire site:
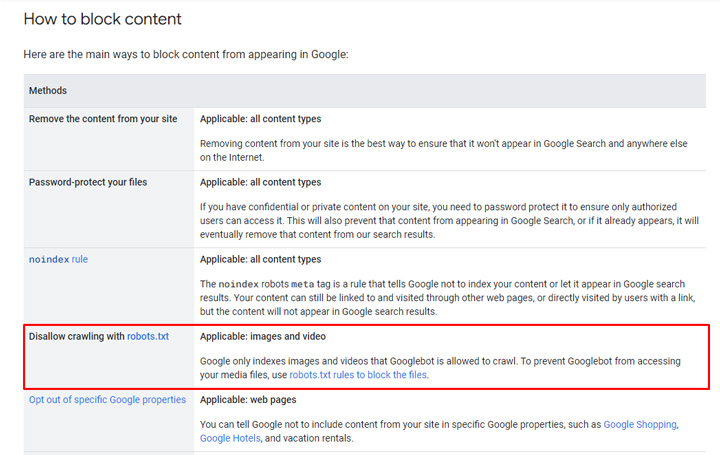
For sites impacted, the solution for having those manual actions removed was simple. Just follow Google’s recommendations for blocking content. For example, you could noindex the content or just remove it completely. Note, although some sites are blocking the content via robots.txt, that’s not a mechanism that Google recommends for blocking html documents. They do have the approach listed in their documentation for images and video, but not for html pages. I’ll cover more about why soon.
So, sites that quickly noindexed the directories or subdomains violating site reputation abuse, or removed those areas completely, had their manual actions removed. And some were removed very quickly. That said, having those manual actions removed didn’t really mean anything from a search visibility and Google traffic standpoint. That’s because the content was now either noindexed or removed! So there would be no recovery for those sites for the content violating Google’s site reputation abuse policy.
Or would there be recovery?? More about that shortly…
How manual actions can fail and why handling spam policies algorithmically (like site reputation abuse) is the way forward.
So why are manual actions not the best path forward for enforcing site reputation abuse? Well, the actions site owners take aren’t foolproof. Some sites have chosen to block the directories or subdomains via robosts.txt, but that doesn’t stop content from being indexed. So those pages could still show up in the search results, but with a message explaining that a snippet couldn’t be generated (since Google cannot crawl the pages).
As of right now, there are sites still ranking extremely well for queries even though those pages are blocked by robots.txt. Note, I don’t know if those sites received manual actions in early May, and had those penalties removed, but there are sites blocking directories or subdomains via robots.txt thinking that’s a valid approach. Like I explained earlier, Google doesn’t list blocking via robots.txt as a valid way to block content for html pages. Again, they just list that for images and video.
Here is an example of one of those sites. You can see that the site is dropping over time, but it’s still ranking well for over 37K queries.
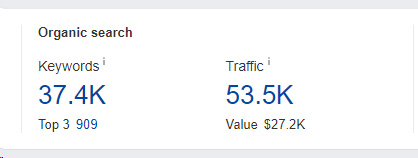
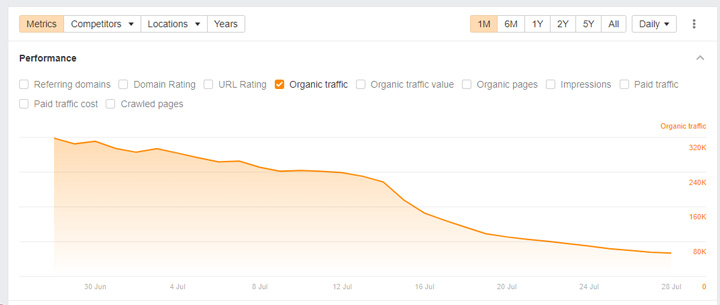
And here is the site ranking well for a coupons query even though the content is blocked via robots.txt. Again, that can happen.
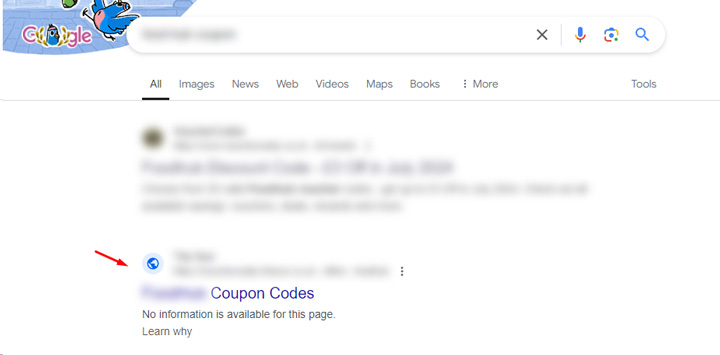
And for sites that had a manual action removed by noindexing directories or subdomains, weird things can happen on that front as well. First, Google needs to crawl those pages in order for the noindex tag to be seen. Until that happens, those pages can rank just as well as they did before the manual action was placed on the site.
Next, and this could be on purpose or by accident, but the noindex tag could be removed for a time, and during that time Google could reindex a lot of the content that is violating the site reputation abuse policy. And then that content can surge back rankings-wise (even if noindex gets placed back for those pages. That can happen since Google would need to recrawl those pages to see the noindex tag again. That’s actually happening right now for a site that received a manual action on May 7th.
Below you can see the visibility trending for the site that received a manual action, noindexed all of that content, had the manual action lifted, but then removed the noindex tag for a bit, which caused a lot of content to be reindexed again. And rankings surged back. The subdomain now ranks for 277K queries again… And to clarify, the pages are being noindexed again right now (after noindex was removed for a bit), but Google has not recrawled all those pages and they remain in the index. I’m sure they will drop out over time, but that’s sure a shot in the arm revenue-wise.
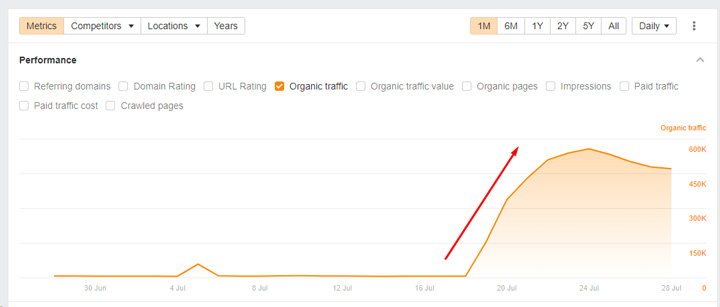
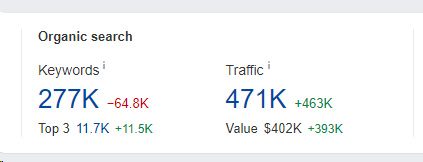
Again, I have no idea if that was just a technical mistake, or if it was on purpose. Regardless, a site can surge back when it shouldn’t – even when violating a spam policy. And then Google would need to pick that change up and handle manually… and the webspam team (humans) would need to decide what to do. Maybe another manual action? And maybe it impacts the entire site versus just the section violating the site reputation abuse policy? Who knows… but for now a site can surge back when it shouldn’t.
And then there are sites that were completely unaffected even though they are clearly violating the spam policy. Many were outside of the United States by the way. Here are sites from three different countries outside of the United States violating the policy yet ranking extremely well. They never received manual actions:
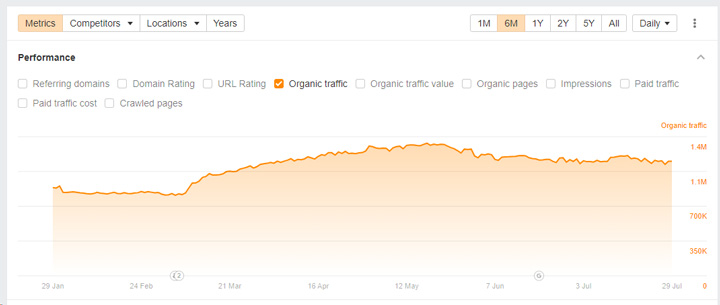
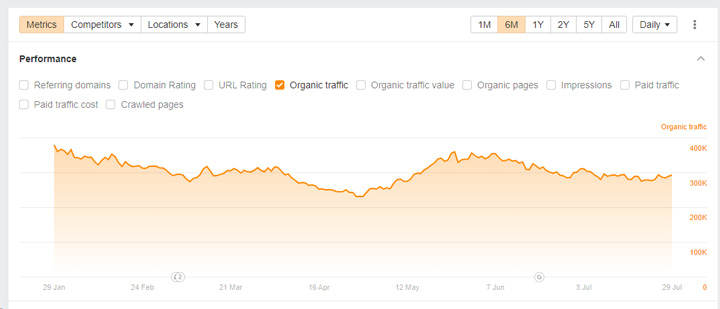
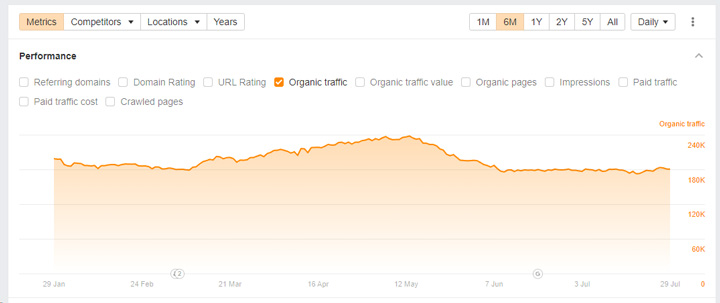
This is why in my opinion an algorithmic approach to handling site reputation abuse is the way forward. Then no matter what happens from a technical SEO perspective with noindexing or blocking via robots.txt, that content will be algorithmically demoted. And since it’s algorithmic, it would probably be a global change impacting sites in many countries (and not just the United States).
Waiting on the algorithmic part of the site reputation abuse policy.
Google’s Danny Sullivan recently announced that the next broad core update is just weeks away. And we also know Google is actively working on the algorithmic part of enforcing the site reputation abuse spam policy. It wouldn’t shock me if handling site reputation abuse was somehow part of the next broad core update (or rolled out around the same time).
But while we wait, Google’s current approach of using manual actions to enforce site reputation abuse has flaws. Blocking via robots.txt doesn’t fully address the problem since that content can still be indexed and rank. And noindexing the content could be reversed, or temporarily removed, which could cause that content to get reindexed and rank again. That’s why an algorithmic approach is the path forward for handling sites violating certain spam policies. One thing’s for sure, it will be interesting to see what the next core update brings. Stay tuned.
GG



