
Hi!
I’m Dan! I think the SEO discipline is a research based discipline. One of my favorite concepts is Garbage In, Garbage Out (GIGO), which I’m going to link to rather then explain but I still expect you to read it! Since bad data begets bad research begets bad tactics begets bad outcomes, I think it’s important to have intellectually honest and valid research.
If only our industry was open to peer review. For those interested in peer reviewing other research, this took me ~60 min all in.
Today I’m going to peer review this study put out by Ryan Jones and Sapient Nitro on Twitter and offer up some counter, contradictory and better research.
Background
Here is the study I’m going to review. I’m just going to be upfront, it’s problematic research. Here’s why:
- It didn’t engage in basic data processing (e.g. removing stop words and other common words). This means that the most common pieces of speech are going to surface in the research, but not insights from keyword choices. While there were later claims that the stop words were the point, I honestly don’t understand why that would ever be the case. Without more effort by the authors here I don’t think this is a good justification. For theme classification, stop words are useless (this includes things like intent, which is itself a theme classification). Anyway, here at LSG we use the NLTK library to pre-process our data. Removing stop and other common words is a basic use-case of that library. Without properly processing and cleaning the data none of the insights are valuable. Remember, GIGO.
- The data set. BrightEdge doesn’t have a very good data set and they aren’t very transparent about how they get it. If you are going to analyze a keyword set that is going to be at best representative (150k keywords is nothing in the keyword corpus of all Search) then you need to make sure it’s as accurate a representation of the true data as possible. If BrightEdge has a less representative keyword corpus than say AHREFs then that would mean again the insights can’t be trusted. Again, GIGO.
Thankfully here at LSG, we know how to remove things like stop words, and other common parts of writing, when processing large amounts of data. I was able to get what I think is a better keyword set to use in the research. And as you will see when I walk you through this and you see the output, it’s just much more useable.
The Research
I got the top 100k keywords by volume from AHREFs thanks to the amazing Patrick Stox after seeing this tweet from AHREFs CMO and being intrigued:
Quick SEO Tip:
An empty search in @ahrefs Keywords Explorer gives you access to our ENTIRE ~4 billion US keyword database (industry’s biggest btw 💪)!
Then use S. volume, KD & Word count filters to find “hi-vol, low-comp” queries.
Perfect for discovering new opportunities! 🔥 pic.twitter.com/BGfrlxQ45s
— Tim Soulo (@timsoulo) August 4, 2021
The Process:
I took the list of top 100,000 keywords by volume and processed the ngrams like so:
Then I took the results (which look like this)
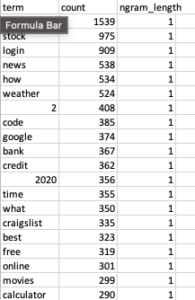
and ran them through the word cloud creator on wordart.com. This is my favorite word cloud creator because it just does a great quick data process. You can remove common words, engage in stemming to roll up close variations, and play with the visual design. 10/10, highly recommend.
And for those that want to argue 100,000 keywords vs. 150,000 keywords; this table will hopefully show you that it’s not super relevant in terms of whose drop of water is bigger:

The Results
There is real info to be gathered once you remove common words like “for” from the analysis. Check it out!

Spoiler – when you perform proper data analysis on data, you can surface some real insights! The most obvious one is that #1 gram, “near”.
I’ve been saying all search is local search for a while. AJ Kohn has been saying it for a while. This is because it’s the reality of the situation. Localization of search results is the #1 trend that SEOs are missing. Primarily because local search has always been looked down as this weird thing that SMBs do. Their loss is our gain I guess 🙂
Another really interesting thing is “vs”. Comparison queries are very popular, and you should be leveraging them in your content if they make sense. The people winning in search already are!
Additionally there are some other insights from this that I would call basic, but good validation. Navigational queries are very high, people like free stuff and stonks, etc.
Anyway, here is the ngram data from the research for those who are interested in examining it themselves. Please feel free to post follow up research, just make sure to give us that link. I’m not going to share the top 100k AHREFs data as you all know where to go if you want to buy it 🙂
![YMYL Websites: SEO & EEAT Tips [Lumar Podcast]](https://www.lumar.io/wp-content/uploads/2024/11/thumb-Lumar-HFD-Podcast-Episode-6-YMYL-Websites-SEO-EEAT-blue-1024x503.png "YMYL Websites: SEO & EEAT Tips [Lumar Podcast]")


