
OpenCV and Tesseract can be associated with Artificial Intelligence due to their involvement in tasks that often fall under the AI umbrella, such as computer vision and text recognition. To automate solving image CAPTCHAs using Java, you will typically need several dependencies for tasks such as image processing, machine learning, and possibly computer vision.
OpenCV: A powerful library for computer vision and image processing. You can use the Java bindings for OpenCV.
Tesseract OCR: Tesseract OCR is an optical character recognition library that extracts text from images.
OpenCV (Open-Source Computer Vision Library)
- Category: AI Toolkit for Computer Vision and Image Processing.
- Purpose: Provides comprehensive tools for image and video processing, essential for many AI applications.
- Capabilities: Includes image transformation, filtering, feature detection, object detection, and support for machine learning and deep learning.
- Usage: Commonly used in AI projects for tasks like object detection, face recognition, and image classification.
Tesseract
- Category: AI Toolkit for Optical Character Recognition (OCR)
- Purpose: Converts images of text into machine-readable text using machine learning techniques.
- Capabilities: Recognizes and extracts text from images, supporting multiple languages and fonts.
- Usage: Utilized in AI projects for tasks such as document digitization, data extraction from scanned documents, and integrating text recognition into applications.
Step 1: Set up Dependencies
First, add the necessary dependencies to your pom.xml file:


Step 2: Write the Java Code
Create a Java class to preprocess the CAPTCHA image and extract the text using Tesseract.
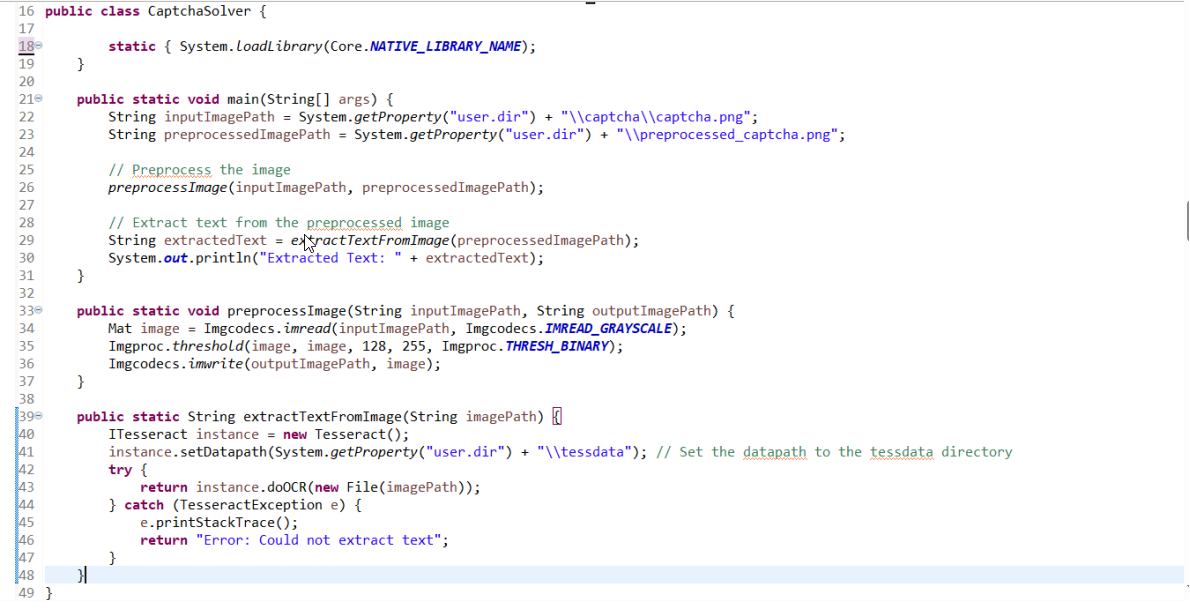
Step 3: Set up Tesseract Data
You must create your Tesseract data files and place them in a project directory (e.g., tessdata). but you do need at least the data file for the language used in the CAPTCHA. Tesseract uses trained data files (often referred to as “language data” or “Tessdata”) to recognize text in different languages.
For example, you only need the English-trained data file if your CAPTCHA contains English text. If contains text in another language, you’ll need the corresponding trained data file.
Step 4: Run the code
Ensure you have an image CAPTCHA in your project directory(e.g.,captcha//captcha.png) and adjust the paths in the code accordingly.

Then, run the CaptchaSolver class.
Final Console Output of Extracted Image Text

Explanation
- Image Preprocessing:
- Load the image in grayscale mode.
- Apply a binary threshold to convert the image to black and white.
- Save the preprocessed image to disk.
- Text Extraction with Tesseract:
- Initialize Tesseract and point it to the tessdata directory.
- Process the preprocessed image with Tesseract to extract the text.
By running this code, you should be able to automate the solving of simple image CAPTCHAs. Adjust the preprocessing steps as necessary for more complex CAPTCHAs.
Summary
Referring to OpenCV and Tesseract as components of an “AI toolkit” accurately reflects their roles in enabling and enhancing AI applications, particularly in the domains of computer vision and text recognition. They are essential tools for implementing AI-driven solutions, making them integral parts of the AI development ecosystem.



