
You’re about to get the strategy behind one of the most challenging SEO campaigns my SEO agency has ever run.
Why was it so challenging? 3 reasons:
- First, the niche is massively competitive: A make-money-online infoproduct in the financial niche. Nuff said.
- Second, we only had 5-months to pull this off.
- Third, just like any other client, they were extremely hungry for results and demanded quality work.
In the case study below, you’re going to learn the technical playbook, the onsite content strategy, and the link building techniques we carried out to get this 45.99% revenue growth win for this infoproduct business.
The Case Study
Our client takes advantage of the wide reach of the interwebs to teach his students how to earn money trading online. We’re talking currencies, forex, stock markets, crypto, etc.
The business’ revenue is generated solely through the sale of digital download products – in this case, trading guides in an ebook format and video trading courses.
When the owner of this profitable business (which already built some authority in the niche) approached The Search Initiative (TSI) about helping to grow their organic reach and find new students, we were excited to take on the challenge in one of the most competitive spaces there is.
There was also a catch – the campaign was planned for only 5 months, which sounded really scary in this case.
To accomplish this, the game plan was to focus hard on a quick-win strategy, while setting the stage for long term gains post-campaign.
Our strategists were certain that the value we could provide would have a considerable impact on his business’ bottom line.
How? Because…
By focusing on increasing organic traffic, we could improve sales, while allowing the client to pull back on ad spend.
Over the course of the campaign, our technically-focused SEO strategies were able to grow organic traffic by 23.46%.
But what did the best job for the client’s business was the 45.99% increase in the number of conversions comparing 1st vs last month of the campaign. Sales went up from just over 2,100 a month to 3,095 – this really bumped their monetization.
And we did it in time.

These gains were achieved within only 5 months of the client signing with TSI and our team starting the campaign.
Here’s how we did it…
The SEO Playbook for Infoproduct Websites
Phase 1: A Comprehensive Technical Audit
I’ve said this in every TSI case study we’ve published so far… and I simply cannot emphasize enough:
A comprehensive technical audit is the most crucial part of any SEO campaign.
So before you begin any campaign, always start with a full technical audit.
Starting with…
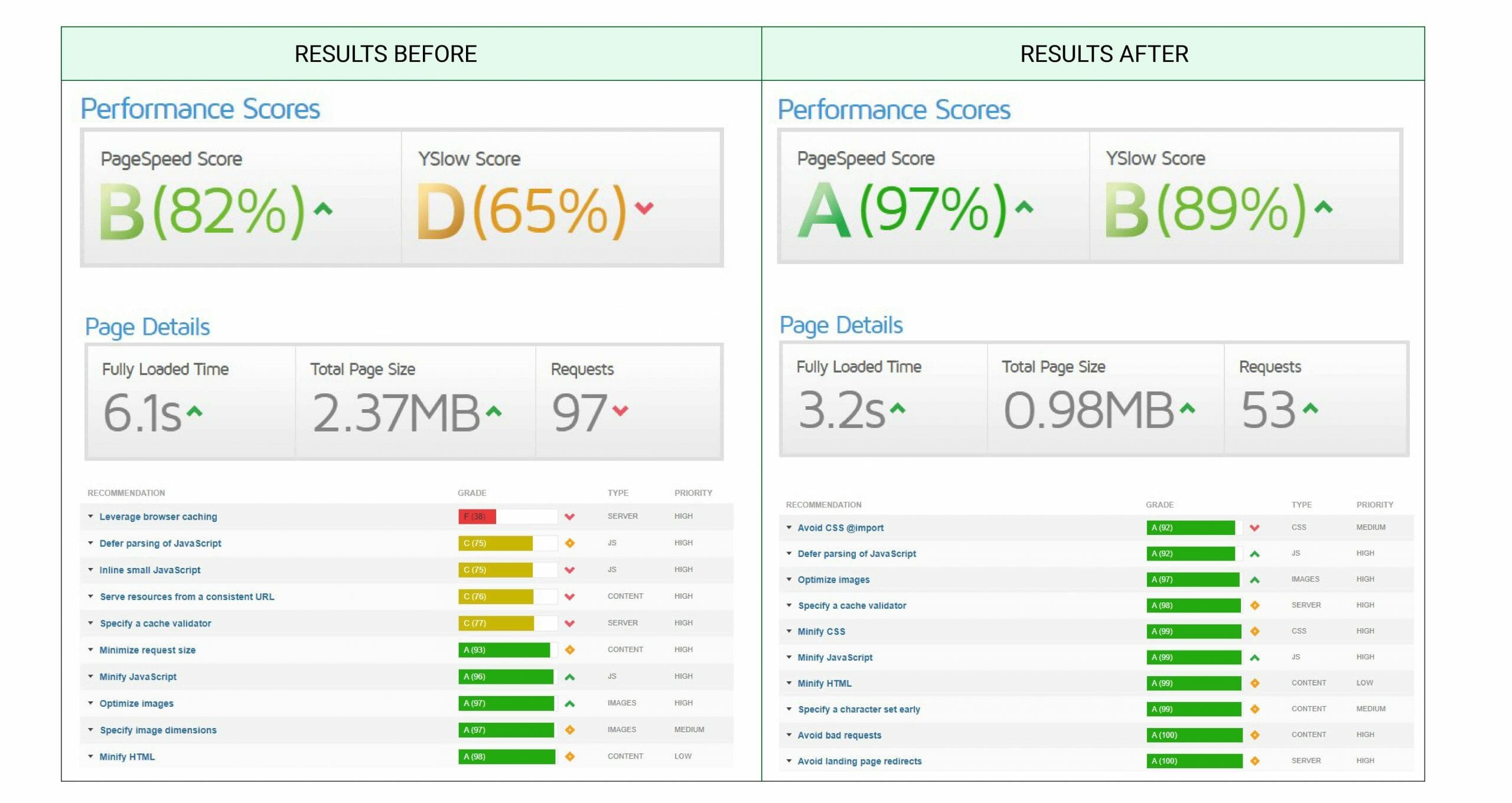
Page Speed
First, our technical SEO strategists started at the bottom of the client’s tech stack… and you should too.
This starts with you digging into the web server’s configuration, and running a series of tests to measure the site’s speed.
This enables you to ensure that the performance of the web server itself wasn’t causing a penalty or disadvantage on either desktop or mobile connections.
So, what tests we run?
- PageSpeed Insights (PSI) – this should be everyone’s go-to tool and shouldn’t need an explanation.
- GTmetrix – it’s good to cross-check PSI’s results, therefore we use at least one other tool. In reality, we use GTmetrix together with Dareboost, Uptrends, and Webpagetest.
- HTTP/2 Test – this one is becoming a standard that can greatly improve your page speed, hence, it’s definitely worth looking into. If you’re not HTTP/2 enabled, you might want to think about changing your server or using an enabled CDN.You want to see this:

- Performance Test – I know it might sound like overkill, but we included this in our test suite earlier this year and use it for the sites that can expect higher concurrent traffic.We’re not even talking Amazon-level traffic, but say you might get a thousand users on your site at once. What will happen? Will the server handle it or go apeshit? If this test shows you a steady response time of under 80ms – you’re good. But remember – the lower the response rate, the better!

In cases where transfer speeds or latency are too high, we advise you (and our clients) to consider migrating to faster servers, upgrading to better hosting or better yet, re-platforming to a CDN.
Luckily, most of the time, you can achieve most of the gains through WPRocket optimization, as was the case with this case study.
Your Golden WPRocket Settings
Cache → Enable caching for mobile devices

This option should always be on. It ensures that your mobile users are also having your site served cached.
Cache → Cache Lifespan

Set it depending on how often you update your site, but we find a sweet spot at around 2-7 days.
File Optimization → Basic Settings

Be careful with the first one – it may break things!
File Optimization → CSS Files

Again, this section is quite tricky and it may break things. My guys switch them on one-by-one and test if the site works fine after enabling each option.
Under Fallback critical CSS you should paste your Critical Path CSS which you can generate using CriticalCSS site.
File Optimization → Javascript
This section is the most likely to break things, so take extreme care enabling these options!!

Depending on your theme, you might be able to defer Javascript with the below:

Note that we had to use a Safe Mode for jQuery as, without this, our theme stopped working.
After playing with Javascript options, make sure you test your site thoroughly, including all contact forms, sliders, checkout, and user-related functionalities.
Media → LazyLoad

Preload → Preload

Preload → Prefetch DNS Requests

The URLs here hugely depend on your theme. Here, you should paste the domains of the external resources that your site is using.
Also, when you’re using Cloudflare – make sure to enable the Cloudflare Add-on in WPRocket.
Speaking of Cloudflare – the final push for our site’s performance we managed to get by using Cloudflare as the CDN provider (the client sells products worldwide).

GTMetrix
If you don’t want to use additional plugins (which I highly recommend), below is a .htaccess code I got from our resident genius and Director of SEO, Rad Paluszak – it’ll do the basic stuff like:
- GZip compression
- Deflate compression
- Expires headers
- Some cache control
So without any WordPress optimization plugins, this code added at the top of your .htaccess file, will slightly improve your PageSpeed Insights results:
Internal Redirects
You know how it goes – Google says that redirects don’t lose any link juice, but PageRank formula and tests state something different (there’s a scientific test run on 41 million .it websites that shows PageRank’s damping factor may vary).
Whichever it is, let’s take all necessary precautions in case there is a damping factor and redirects drop a % of their link juice.
Besides, not using internal redirects is just good housekeeping. Period.
As we investigated the configuration of the server, we discovered some misapplied internal redirects, which were very easily fixed but would have a considerable effect on SEO performance – a quick win.
You can test them with a simple tool httpstatus.io and see results for individual URLs:

But this would be a long way, right? So your best bet is to run a Sitebulb crawl and head over to the Redirects section of the crawl and look at Internal Redirected URLs:

There you will find a list of all internally redirected URLs that you should update and make to point at the last address in the redirect chain.
You might need to re-run the crawl multiple times to find all of them. Be relentless!
Google Index Management
Everyone knows that Google crawls and indexes websites. This is the bare foundation of how the search engine works.
It visits the sites, crawling from one link to the other. Does it repetitively to keep the index up-to-****, as well as incrementally, discovering new sites, content, and information.
Over time, crawling your site, Google sees its changes, learns structure and gets to deeper and deeper parts of it.
Google stores in their index everything it finds applicable to keep; everything considered useful enough for the users and Google itself.
However, sometimes it gets to the pages that you’d not want it to keep indexed. For example, pages that accidentally create issues like duplicate or thin content, stuff kept only for logged-in visitors, etc.

Google does its best to distinguish what it should and shouldn’t index, but it may sometimes get it wrong.
Now, this is where SEOs should come into play. We want to serve Google all the content on a silver platter, so it doesn’t need to algorithmically decide what to index.
We clean up what’s already indexed, but was not supposed to be. We also prevent pages from being indexed, as well as making sure that important pages are within reach of the crawlers.
I don’t see many sites that get this one right.
Why?
Most probably because it’s an ongoing job and site owners and SEOs just forget to perform it every month or so.
On the other hand, it’s also not so easy to identify index bloat.
With this campaign, to ensure that Google’s indexation of the site was optimal, we looked at these:
- Site: Search
- Google Search Console
In our case, we found 3 main areas that needed attention:
Indexed internal search
If you’re on a WordPress site – you have to pay attention to this one.
Most of WordPress websites offer a built-in search engine. And this search engine is usually using the same pattern: ?s={query}.
Bear in mind that ?s= is the default one for WordPress, but if your theme allows you to set this up yourself, you might end up having something else instead of the “s” param.
To check if this is also your problem, use this site: search operator
site:domain.com inurl:s=

If it comes back with any results, it means that your internal search pages are being indexed, you’re wasting Google’s crawl budget, and you want to block them.
For our client, we suggested implementing noindex tags.
If your SEO plugin doesn’t have the option to noindex search results (I know that Rankmath does, but can’t remember if Yoast offers it as I’ve been off Yoast for a long time now), you might alternatively add the following line to your robots.txt:
Disallow: *?s=*
Duplicate homepage
This is another fairly common issue in WordPress if you’re using a static page as your homepage.
You see, the CMS may generate the pagination on your homepage, even if you don’t really have it paginated.
Why does this happen? Well, usually when you have a section where you list some of your newest posts. Or (thank you WordPress!) when you used to have your homepage set up as “Latest Posts” and Google managed to index them.
This creates URLs like these:domain.com/page/12/
domain.com/page/2/
domain.com/page/7/
domain.com/page/{number}/
The problem is caused because Google sees different content on these pagination pages – of course, the articles on page 2, 3, x are different, so the paginated list changes.
If you don’t have enough of the other, non-listed content on your homepage, to convince Google that these pages are similar enough to obey canonical – you have a problem.
In this case, even if you have the correct canonical tags in place, but Google finds these pages to not be identical, it might choose to ignore the canonicals. And you end up having all this stuff in the index.
It’s worth a check if you have similar pages indexed – and you should definitely pay attention:
To find these, run another site: search:
site:domain.com/page

To solve this for our client, we set up the 301 redirects so all of these pagination pages were pointing back to the homepage and we also removed them from XML sitemap:

(If you’re wondering, this screenshot is from Rank Math, which is a great free Yoast alternative, but you can also use Redirection plugin for WordPress.)
Please note that if your homepage is set up as a blog page (see below screenshot), this is most likely NOT a problem!

Other unwanted indexed pages
In our case, we also found other pages that were indexed but shouldn’t be:
- Old forum pages
- Old template pages
- Blog tags
- Media pages (thanks again, Yoast…)
Each of them might be different in your case, so you might want to consult an agency or professional SEO.
For this client, we removed the pages and used a 410 Gone HTTP header to remove them from the index faster.
Protip: Site: search queries you need to know
site:domain.com
This one is your foundational search queries and allows you to go through the entirety of what Google has indexed under your domain.
I like to run a search like this and switch to 100 results per page, by adding a num=100 parameter on Google:
https://www.google.com/search?q=site:domain.com&num=100
Then, I just click through the SERPs and inspect what’s there.
Things that are the most common issues are:
- Query strings
- Login/Cart/Checkout
- Pagination
- Tags
- Anything that surprises you 🙂
Note that it doesn’t work for big sites as Google will only show you a sample of URLs.
site:domain.com/{folder}
This is just an extension of the standard site: search and allows you to find everything in a folder.
For example, on a Shopify site, you can list all category pages by running this search:
site:domain.com/collections/
Moving on…
site:domain.com inurl:{part-of-the-URL}
I **** this one. It allows you to list all pages that share a common part of the URL.
For example, let’s say you want to find all pages that have “guide” in the URL:
site:domain.com inurl:guide
Voila!
site:domain.com -inurl:{part-of-the-URL}
Did you notice the little minus sign here “-inurl”? This one allows you to list all URLs that do not contain a certain string in the URL.
Let’s say you want to list all pages that do not contain “blog” in the URL.
Here’s how you’d do it:
site:domain.com -inurl:blog
The combination: site:domain.com -inurl:{part-of-the-URL} inurl:{another-URL-pattern}
Get ready for a really serious tool now! This one is a combination of “inurl” and “-inurl” (not in URL) operators and allows you to list pages that have a specific string in the URL, while don’t have another part in it.
For example, if you want to list all pages that are guides on your site, but not the buying guides – here’s how:
site:domain.com inurl:guide -inurl:buying
Make sure not to use spaces between the “:” and the string!
Also, be careful with the queries where operators cancel each other out – Google won’t return any results for these!

There are plenty of other combinations and search operators, so if any of the above is new to you, you should definitely read more about them here:
https://ahrefs.com/blog/google-advanced-search-operators/
Get Your Sitemap in Order
In this case study, the team ensured that the XML sitemap was configured correctly so that Google’s crawlers and indexation engine were able to fully understand the site’s structure and present it to their users accurately.
Run a crawl with Screaming Frog to ensure that no URLs that are noindexed or missing are added to the sitemap.
First, switch to “List Mode” in Screaming Frog. Then select Upload → Download XML Sitemap. Type in the URL and let it crawl.
There should be no other pages than only the ones returning a 200 status code.
If there are, just remove them from the sitemap!
Soft 404 Errors
Soft 404 is a URL that displays a page telling the user that the page does not exist, but it returns a 200 OK (Success) instead of a 4xx HTTP status code.
This can definitely be a big problem for your site because, when it occurs, Google will start selecting what it thinks is a 404 with incorrect (200) HTTP response code on its own and, let’s be honest, algorithm sometimes often gets it wrong!
So, you’re facing an issue that good pages, which you’d rather keep in the index, are being thrown out because Google thinks they’re 404s.
Why does it think so?
Most probably there are similarities between the genuinely good and Soft 404 pages.
Unfortunately, these similarities are not obvious and, when analyzed algorithmically, they can be mistakenly taken as anything common and silly: footer, sidebar, banner ads, or whatnot.
So let me give you an example – this is how my 404 page looks like:

It returns a correct 404 status code, so everything is fine:

Now, if it was returning a 200 code – it would’ve been a soft 404. Google would figure it out and it could all be fine.
But there’s a but.
Let’s say I had a page with just a little bit of content – like this made up one:

As you can see – it has a different content, but everything else is the same: header, sidebar, footer.
When you approach it as Google does – algorithmically, it might end up being very similar to the soft 404 page example above. In fact, Google may class it the same. And this is what you don’t want. You don’t want Google to decide for you.
My rule is – don’t allow Google to make any decisions for you!
Our job, as SEOs, is to make it ridiculously easy for Google to crawl and index your site. So don’t leave anything you don’t have to for the algorithm to figure out.
In this case, we had all 404 pages set up to 301 redirect back to the homepage. It’s a common practice, but occasionally a dangerous one.
Why would it be dangerous?
Because we’ve seen cases where Google would simply treat all 301 redirects to the homepage as Soft 404s. And when it does that, it might also start treating your homepage as a Soft 404 page, because all these Soft 404s are defaulting to your homepage, right?
And what does that mean?
No homepage.
And when there’s no homepage? No rankings!
But if you’re really unlucky, Google will think that if your homepage got removed (Soft 404’d and thrown out of index), your entire domain should go out the window! And it’ll go on and de-index everything.
Sounds harsh!? It does, but we’ve seen extreme cases like this, so it’s better to be safe than sorry.
So why were we comfortable doing it?
At TSI our approach to this is simple: 404s are a natural thing on the Internet!

Therefore, we only 301 redirect the important pages, where applicable. By important, I mean pages that have external or internal links and some history.
We leave 404s where its a legit page of content just removed from the site, but has no value anyways.
I know what you’re thinking: What about Excluded or Errors under Index Coverage in Google Search Console?
To put it simply, in this case – Nothing! Because 404s are normal. Google will report them in GSC, but that’s fine.
Fixing Facebook Pixel Issues
Most infoproduct businesses leverage Facebook retargetting, so if you have an infoproduct (or your client does) you need to consider the following issue.
This problem was quite tricky to find a solution to, but our crawls showed that spiders can follow a pixel image:
![]()
So as you can see (or not see, because most of it is blurred) above, crawlers were accessing pages like:
domain.com/“https:/www.facebook.com/tr?id={client’s FB ID}&ev=PageView&noscript=1”
The part in red shouldn’t be there. As you can imagine, this was the case for every single URL on the site. Not good!
We didn’t really know how this was possible or what caused it, but the plugin generating Facebook Pixel was doing it wrong…
The problem was the backslashes “escaping” single and double quotes in the Javascript code generating the pixel:
![]()
We retired the plugin and inserted the pixel code directly in the source code (header.php file).
Our tech SEO guys keep complaining that there’s a plugin for literally everything in WordPress. Even for the easiest and smallest things.
So maybe next time, when you’re thinking of installing a plugin do us and yourself a favor – think if it’s really needed.
Don’t use plugins where they’re simply an overkill and the same can be accomplished faster and smoother by just a simple copy-paste.
Heading Structure
This was quite simple, but also an important one.
This site did not use any headings other than H2s… None. At all.
I mentioned the importance of semantic headings in another case study, so I’ll just say that the fix here was to simply organize them on every page and use all headings from H1 to H5.
Simple, but important.
Learn more about heading structure in my Evergreen Onsite SEO Guide.
HTTP pages and YMYL
Non-secure webpages are quickly going out of style.
The Electronic Frontier Foundation is aggressively promoting the movement of the secure HTTPS protocol being used across the entirety of the web.
Google is also supporting the idea through flagging of non-HTTPS content as “not secure” in Chrome.

This client did indeed have the correct SSL implementation in place, but there was a big problem.
The old HTTP pages were not redirected to their HTTPS versions.
Being in the YMYL (Your Money or Your Life) niche, you shouldn’t leave any loose ends.
I mean, you shouldn’t leave any loose ends at all, but when you’re in the YMYL niche specifically, you simply must not.
You could fix it with the use of Really Simple SSL plugin, which enables the HTTP→HTTPS redirects out of the box.
But as I said above, you don’t need WP plugins for every small action.
Here’s the .htaccess code we installed to have a proper HTTP to HTTPS and non-www to www redirect in place:
RewriteEngine OnRewriteCond %{HTTP_HOST} !^yourdomain.com [NC,OR]RewriteCond %{HTTP:X-Forwarded-Proto} =httpRewriteRule ^(.*)$ https://yourdomain.com/$1 [R=301,L]
Be careful, though! Make sure you have access to your FTP server before you click “Save” in the configuration.
In some cases, it might break things and to re-gain access to your site you’ll have to manually amend the contents of your .htaccess file.
All in all, this is what you want to see if your preferred canonical domain is https://domain.com/:

Content Taxonomy & Internal Linking
In order to improve the internal linking of our client’s numerous blog posts, we recommended a re-organization of the site’s content categorization and taxonomy.
To start with, we suggested creating more categories in WordPress and adding them to the main menu.
This sounds simple, but prior to joining TSI, this site had only 1 big category (about 300 posts): Blog.
Moreover, to save the crawl budget, someone, unfortunately, noindexed all category and pagination pages.
When guys at TSI saw it, they were like this:
See what I mean here? We’re all about them quick wins.
We also removed the noindex tags from the category pages.
The final trick was to add short, topically relevant text on top of each category page (above the posts), so Google would see them as more than just a list of articles. It meant more **** from the G!
Kind of like what I’ve done here for my “SEO News” category page.
Through this, we created topical clusters (silos) under each category.
To create better topical relevance, you can also ensure that the articles would in most cases internally link only within the silo (article to article and article to its root category page).
This helps to better organize the content for the user’s benefit and also made it easier for crawlers to discover the pages.
The process built more internal links to the content, indicating its importance within the site’s information architecture.
A related posts content section was also added beneath each blog post, which amplified the same benefits, as well as providing the additional pros of helping users to find more of our client’s relevant educational content, also improving user metrics and click-through.
Stack those gains!
Phase 2: Creating a Winning Content Strategy
Once the server, site, taxonomy, and Google index were in advantageous positions, it was time to think about creating targeted content that both served the target demographic and would have the potential to rank for their most essential search terms.
Using Ahrefs, our technical team looked at competitor content for potential target keywords and studied metrics that indicated how difficult it would be to rank against them.
Trust me, once you have a list of keywords or topics you’re considering to go after, Ahrefs’ Keyword Explorer becomes very helpful:

And to find great keyword suggestions, from the Keyword Explorer you just need to go to Newly Discovered and you’re seeing all examples of new keywords related to your chosen one:

Another worthwhile option is Questions:

From there you can just pick keywords that appeal to you, taking into consideration their difficulty vs search volume.
But if you really want to up your content plan game, you have to check out the Content Explorer on Ahrefs:

It’s an extremely powerful tool, so I suggest you watch the below video to really take full advantage of it:
For our client, we estimated average monthly search volumes and considered the probable user intent behind each keyword vertical.
And speaking about the user intent – trust me, this is already a huge factor, but it will get even bigger in 2023.
If you would like to learn more about user intent, its types, and discovery, we had a great workshop during the Chiang Mai SEO conference this year. Here’s a video of one of TSI’s resident geniuses, Rad Paluszak, who held the presentation:
This content research process will give you the information needed to construct a strategy that focuses on creating content to serve users searching for the highest opportunity keywords.
Content Optimization & Keyword Cannibalization
The next task was to look at the existing pieces of content in 2 ways:
I’ve talked about keyword cannibalization quite a bit in the past.
In fact, I think this is one of the most common, content-related on-site issues of this year.
It’s a plague on the industry, I tell you!
At TSI, we’re predicting that keyword cannibalization issues will become less of a problem with Google becoming smarter in natural language understanding (hint: Neural Matching and BERT), but it will probably remain as a *** topic and a big problem for years to come.
So in this case, we faced quite a serious case of keyword cannibalization. Out of around 300 articles indexed, 50 of them were double- or triple-ranking (cannibalizing) around positions 20-40. This was a strong suggestion that it needs to be solved.
This is just one of the keywords:

Since we are not experts in market trading and financial instruments, we had to ask the client for advice. We combined the list of all cannibalizing URLs and keywords, and supplied it to our client for a review.
When we received feedback regarding which pages can be merged, deleted or updated, the work began: We moved and combined the content.
And this is what you want to see:

In the meantime, we purged the pages that were not required and optimized (or deoptimized) the ones that were not preferable but had to stay within the site.
In doing so, we were able to increase the value of the existing content and get the most traffic possible from the client’s previous investment in the content.
Phase 3: An Authority Link Building Strategy
An essential part of any high-impact SEO campaign is the building of high-quality backlinks.
When this client joined us, we did the standard thing we do on every campaign, which you should do as well.
Perform a full audit on your backlink profile and you’ll likely find a mix of lower quality backlinks and some higher-quality inbound links too.
Immediately, some of the lowest quality backlinks were disavowed. You can read more about our approach to the backlink audit here.
Also, do an audit of your anchor text distribution.
In our case, we were slightly concerned about the anchor text distribution having too many exact match, partial match and compound (related to keywords, but not necessarily including the keywords directly – examples of these would be questions, sentence-long anchors, etc) anchors.
It looked like this:

And should look more like this:

With this in mind, during the first month of the campaign, we threw around 25 pillow links (we really propped up client’s social media accounts, created a few About Author pages on the publications he’s been contributing to and posted a few Medium articles) with branded anchors into the mix.
In the next 2 months, we also took a slightly safer approach to anchor texts in our outreach. This was all to balance things out.
Our outreach team began the process of reaching out to relevant sites who were pleased to place our client’s backlinks on their domains.
In the first month, the team negotiated and built 9 strong (DR 50+) outreach backlinks to the site and were able to negotiate 5-8 high-authority links each ongoing month.
Here are some link stats of our outreach job:



This quickly grew the domain’s authority, thus driving up rankings and improving discoverability on the web.
Here’s the link growth over the course of the campaign:

Results
Through completing our campaign using the techniques described in this case study, we were able to achieve considerable tangible growth for this client.
After 5 months of TSI working on the site, the client had enjoyed a 28% growth in the top 10 position rankings in Google, up from 1,713 positions to 2,188.

Stable growth is also shown in SEMRush:

This significantly increased the education business’ organic reach within just 5 months and translated into a 23.46% increase of sessions, an 18.46% increase in users and a 45.99% increase in earnings when comparing the 1st and 5th months of the campaign.


Comparing month-to-month with the previous year, with our help, the site reached a 252.78% increase in organic traffic and a 263.24% increase in goal completion.


The results of this campaign speak for themselves.
After 5 months of working with TSI, our client had seen a nice return on investment, and our proven strategies will continue to bear fruit as the business continues to develop in the long-term.
Conclusion
When a client puts their trust in you, you need to look at it from their perspective.
They’re trading their hard-earned cash for you work on their business, their baby.
With this particular case study, the pressure was on with a 5-month timeline in one of the hardest niches imaginable.
But by focusing on quick wins and optimizing what the client already had, results like this are achievable.
Let’s recap… remember to focus on:
- Technical SEO first – Without a strong boat, you’re not going to sail anywhere. Don’t skip anything in the tech-SEO section above.
- Content optimization and strategy – This is the area you want to bank on in the coming years.
- Quality Backlinks – Focused on authority and balanced anchor distribution.
As long as you’re doing the right things: fixing everything, providing value and making the site easy for Google to understand – you’re going to win.
And if you need help, you know where to find us: The Search Initiative.
Get a Free Website Consultation from The Search Initiative:




