

Everybody is talking about keyword clusters. At the core, it’s pretty simple – group related keywords together. Sounds easy, right?
Some free tools walk you through some basic Natural Language Processing (NLP) that help deduplicate and find semantic similarities between keywords. There’s nothing wrong with starting there, but those are inevitably limited. Google, on the other hand, has infinitely more data to feed into its algorithms, including on-page data and links to provide more context than just basic keyword manipulation.
To truly understand how Google sees the world, you must collect SERP data to see which pages rank for which terms. At scale, by comparing how many URLs overlap in the top 10 results, you get a very clear picture of which SERPs are related. This method has been recently popularized by Keyword Insights, also available from Nozzle, Cluster AI, and others.
I am continually surprised when I find keywords that I would have manually grouped together, but Google shows zero overlapping URLs, and vice versa. Whether or not Google is “right” in these cases is irrelevant – it’s Google’s world, and we just live in it.
Here are the results when you search for “SEO agencies” and “SEO companies” side by side with ads removed, and you can see that eight of the top 10 are the same!

Manually finding these overlapping pages is nearly impossible to do at scale but trivial for good tooling. For years now, there have been various tools that help curate keyword lists but fail to dig deeper. There’s even a big new kid on the block offering basic clustering, but their 2,000 keyword limit is disappointing.
Automatically clustering your keywords is great, but this is where most tools end – a list of keywords, maybe search volume and/or rank. Here is a wishlist of 10 types of data that would be invaluable in the context of keyword clusters, most of which have been unavailable to ****.
- Ranking URLs
- Refine by
- PAA
- FAQ
- SERP features
- Search intent
- Ranking position
- Share of voice
- Entities
- Categories
1. Ranking URLs/pages
Existing tools are not showing you exactly which pages are shared between all the keywords in the cluster, which makes it very difficult to learn what Google is rewarding. Additionally, knowing the number of URLs gives significant insight into the strength/tightness of the cluster. Like in the example above, sharing eight out of 10 URLs is a very tight cluster, where only 3-4 overlapping pages are moderately tight.
Most tools also force you to decide before you get started about how many overlapping URLs to count, which is hard to know before you see the data. You should be able to dynamically change this value as you explore and without having to pay to run the clustering process again.
If you have any experience with content writing tools, they will often scrape the top results for a single keyword for you to see. It is much more effective to scrape the URLs ranking for ALL THE KEYWORDS in the cluster!
Seeing detailed information about their headings, schema, and text stats like word count/grade level can be a helpful guide.

2. Refine by
One criminally overlooked source for relevant topic information is hidden right at the top of every SERP, helpfully labeled with the hidden H1 tag, “Filters and Topics”.
After a few traditional tabs like Images, News, Maps (changes from search to search), Google links to related topics, typically prepending or appending the topic to the current keyword phrase. These are generally easy to identify manually and can also be differentiated by HTML markup/CSS classes.

3 and 4. People Also Ask (PAA) and frequently asked questions (FAQ)
People Also Ask questions are a goldmine for content creators, as Google gives you the blueprint for what to answer in your content. PAAs are also much more volatile than traditional search results, so by aggregating them over time rather than a one-time scrape that most tools use, you can identify which questions appear the most often. In our example above, even though the SERPs were nearly identical, there were zero overlapping questions.
First, we have the top 10 questions for this specific cluster over the last 30 days. SERP count is the total number of SERPs they appeared on, and keyword count is the number of unique keywords that showed the question.
Very similar to PAA, below are the questions that Google deemed relevant enough to the topic to provide significantly more visual real estate to the site by implementing correct schema.org markup.

5. SERP features
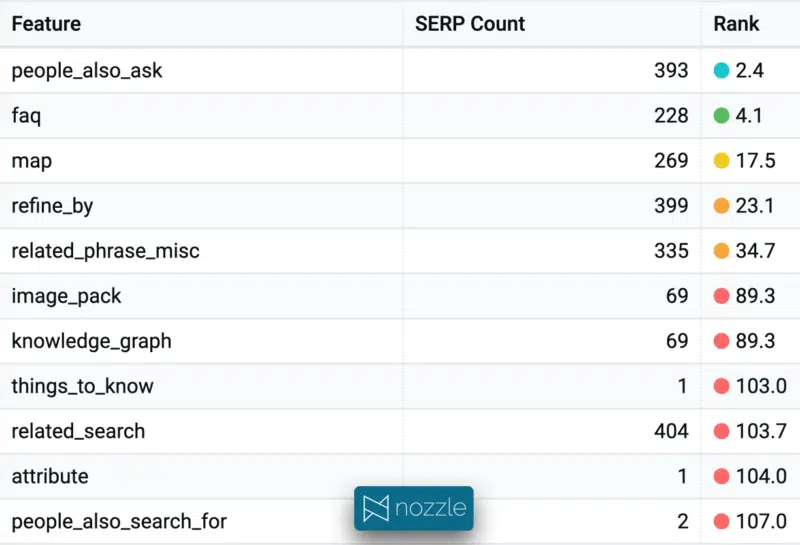
The presence or absence of specific SERP features for a cluster will impact your content strategy. PAA and FAQ typically get very high visibility on the SERP – for this cluster, ranking position 2.5 and 4.2, respectively – so adding the correct markup and answering the right questions can drive significant traffic if you can capture it. Maps show 65% of the time, which signals some fractured intent. Things_to_know is only visible on a single SERP but might represent a growth opportunity if you optimize.
6. Search intent
Search intent influences your entire strategy, so knowing the overall cluster intent, including mixed intent, is crucial to a great strategy. Search intent should also be available per result, in addition to an overall aggregate score, to help identify opportunities to rank multiple pages on a single SERP. Having data that informs that intent, like Google Ads metrics, is also useful.
7. Ranking positions
Reporting your current ranking position is vital. If you don’t currently rank at all, there might be some low-hanging fruit where you simply have a content gap, and with sufficient topical authority, you could rank just by publishing. Similarly, if you rank 8-15, you might be able to 10x your traffic with just some extra optimization.
Bonus points if you can see more than just rank, including newer metrics like pixel depth and above-the-fold %.
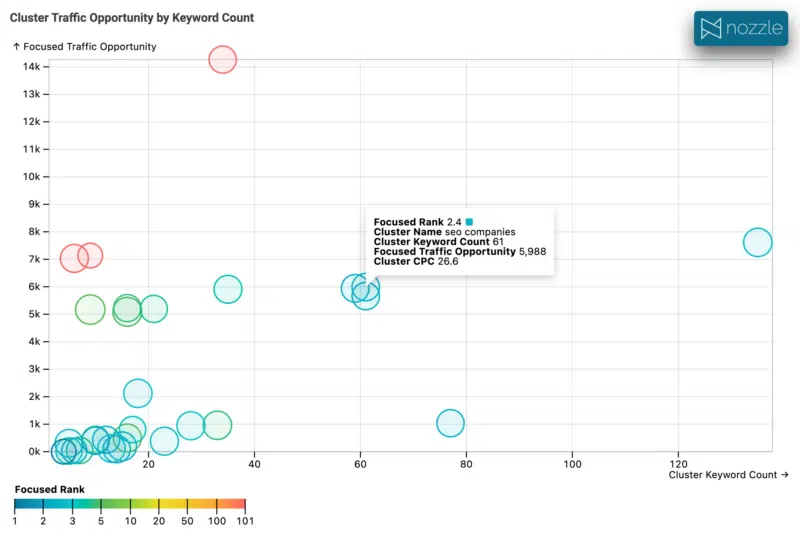
Having the rank available doesn’t mean much if you can’t meaningfully visualize it to identify opportunities.
This shows the number of keywords in a cluster against search volume, with CPC as the bubble radius and rank as the bubble color. It’s easy to quickly identify clusters matching your criteria to drill into for more detail.
8. Competitive overview/Share of voice
Seeing your own rank is great, but it’s even better if you can spy on your competitors with the same data. Switching between domains gives you god-like powers to dominate your competition.
Since every cluster is different, there might be a different set of competitors in each one, so make sure you can report on the share of voice per cluster.
9. Entities
Google has long since stopped seeing the web via exact-match keywords. It’s more about semantic similarities, which can be represented by entities extracted from page content using natural language processing (NLP).
To learn more, I highly recommend reading Timothy Warren’s article on SEL, “Entity SEO: The definitive guide.” While there are many APIs and open-source tools like spaCy to extract data from text, I prefer to use Google’s API, and they have a demo, as shown below, identifying important parts of the text.
- Salience: the importance of the entity to the text.
- Sentiment Score: from -1 to 1, with -1 being the most negative, 0 neutral, and 1 being the most positive.
- Sentiment Magnitude: indicates how much emotional content is present within the document.

As a content writer targeting a keyword cluster, hopefully, you’ve evolved past keyword density. However, it’s still important to ensure you correctly target entities that Google knows and cares about.
Now let’s say that we’re writing for Bruce Clay, and we have decided to target this “SEO companies” cluster example. Normally the workflow would involve the writer scanning a few important pages, then updating an existing page. With entities, we have a new way to approach content optimization. We can use the same NLP to extract entities from our mapped page, then compare them with the cluster entities.
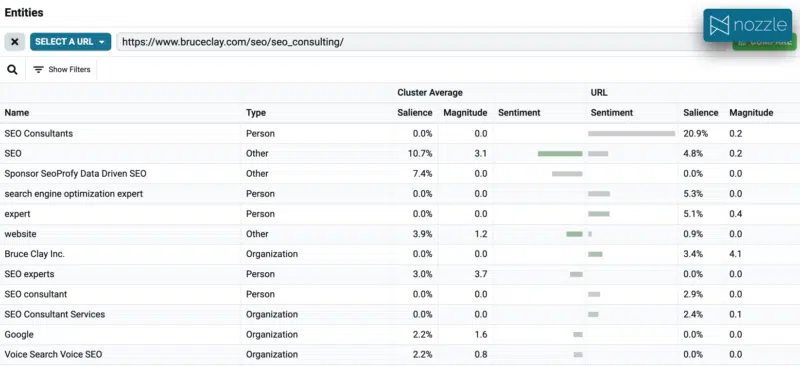
In this case, it is very clear that there is a total mismatch. Assuming the page you are comparing already ranks for other clusters, this is a strong signal that you need to create new content to target this cluster.
10. Content categorization
Similar to our approach to entities, we can also categorize our content, and by comparing that to the cluster, we can identify mismatches.
Google has a classification API with nearly 1,100 categories that work across multiple languages. Unsurprisingly, SEO is the leading category for this cluster’s matching URLs, but category #4 is “Product Reviews & Price Comparisons.”
At that confidence level, that doesn’t mean you need to run and add a comparison table to your page, but it’s worth considering if that would add value to your audience.

Conclusion
Until now, you’ve had to stitch together different tools to see even a fraction of this data. Today, Nozzle is launching our keyword clustering tool on Product Hunt, with all this data at your fingertips. Come and try it out on your own keywords for free!
Source link : Searchengineland.com



