
As a website owner, you ought to know that SEO is essential for boosting your site’s visibility and driving traffic there. Optimizing the JavaScript on your website can improve its ranking, but how do you even begin to tackle the complexities of JavaScript SEO?
In this blog post, we will explore the most common issues with utilizing JavaScript for SEO and provide solutions on how to fix them quickly. Whether you are already familiar with coding or new to optimizing content for web crawlers, this article will show you how to fix any JavaScript issues that might be affecting your rankings.
Can JavaScript errors affect SEO?
Simply put, yes, JS issues can hurt your search engine optimization efforts.
Search engine bots can encounter issues when crawling sites that rely heavily on JavaScript for content. This can result in indexing a website incorrectly or, worse still, not indexing it at all.
For example, due to the complexities of JavaScript, crawlers can misinterpret certain coding elements, which can lead to content not being properly indexed. As a result, any website that relies heavily on JavaScript can suffer from a decreased ranking.
Generally, the more complicated your coding is, the more likely it is to suffer from JS issues that affect SEO. However, the good news is that there are methods to fix these errors and therefore improve your website’s ranking.
The most common SEO JavaScript issues
Now that we have established that JS issues can, in fact, hurt your SEO efforts, let us look at some of the obstacles that you are most likely to encounter.
JS (and CSS) files are blocked for Googlebot
It is crucial that crawlers are able to render your website correctly, which requires access to the necessary internal and external resources. If your site is not rendered as expected, then Google may do so incorrectly, leading to differences between how the page appears to a regular visitor and to a search engine bot.
A common problem is blocking important resources in the robots.txt file.
JavaScript and cascading style sheets (CSS) files are crawlable and renderable by Googlebot, so the reading of them in your website’s robots.txt should not be intentionally prevented. Blocking the crawling of JS and/or CSS files in this way, on the other hand, would directly impact the ability of bots to render and index your content.
So, what to do about it?
You can verify how your pages are rendered by Google by using the URL Inspection Tool in Search Console. It is best if you test several exemplary URLs per site section that uses an individual template.
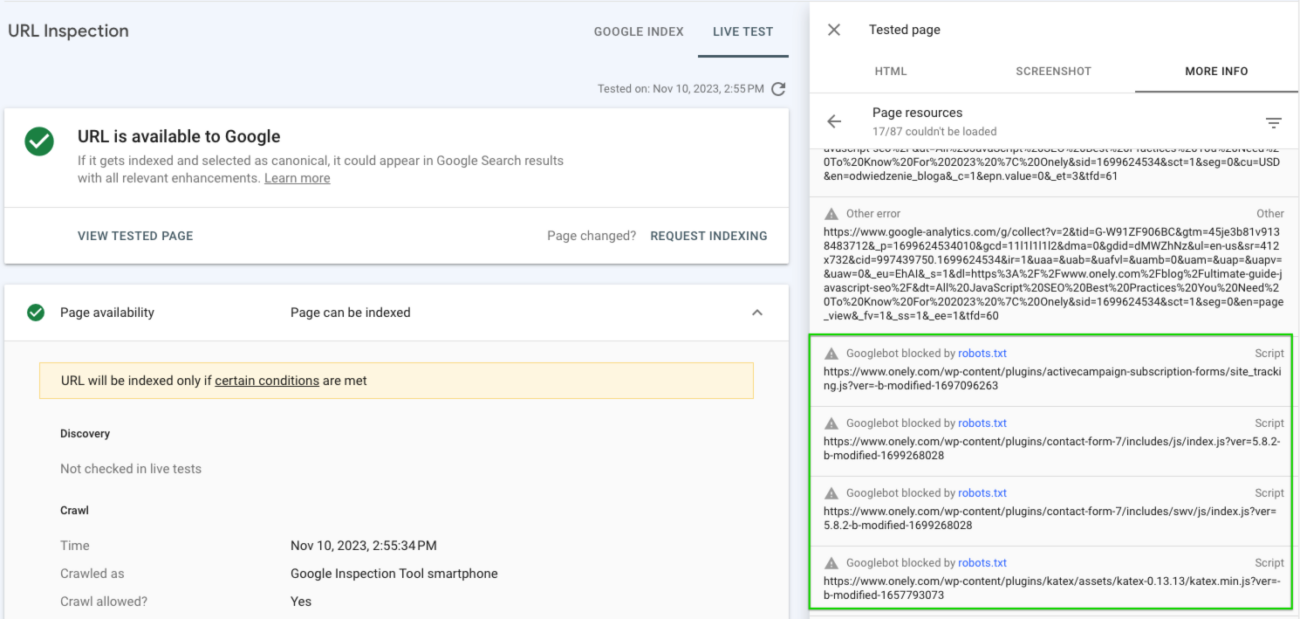
Open the image in a better resolution
A critical question is:
Do resources that are not loaded add any significant content to the page and should be crawlable instead?
Also, examine your robots.txt file – are any relevant directories that store assets blocked for Googlebot?
If so, remove any blockades that target critical files.
You are not using <a href> links
HTML links (hyperlinks with <a> tag and href attribute) should be used to link to indexable pages so that search engines can:
- crawl and index your pages
- understand the structure of your website.
JavaScript-generated links may prevent Google from doing so, because Googlebot does not interact with the pages like users do, or perform actions such as clicking.
Google’s documentation provides examples of problematic implementations:
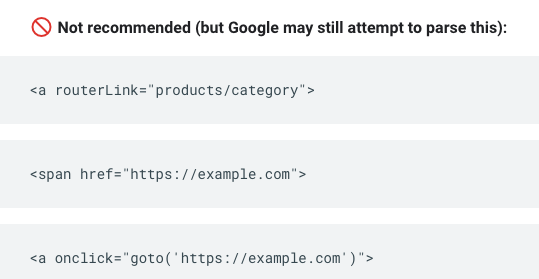
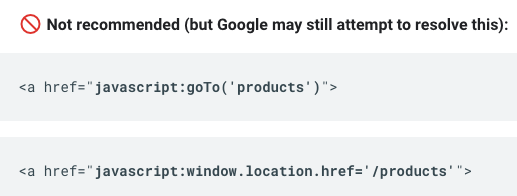
For example, if you are using pagination – the separation of digital content into discrete pages – links that depend on a user action such as a click handled with JavaScript, will likely prevent Googlebot from visiting any subsequent pages.
If your paginated pages lead to unique indexable URLs, it is essential to use <a> links for pagination, so that Google can discover and index the additional content on any following pages (such as product pages linked from paginated categories).
For example, Fenty Beauty’s category pages use a Load More button to reveal more products without any <a> tag links that would be visible to web crawlers.
https://fentybeauty.com/collections/makeup-lip
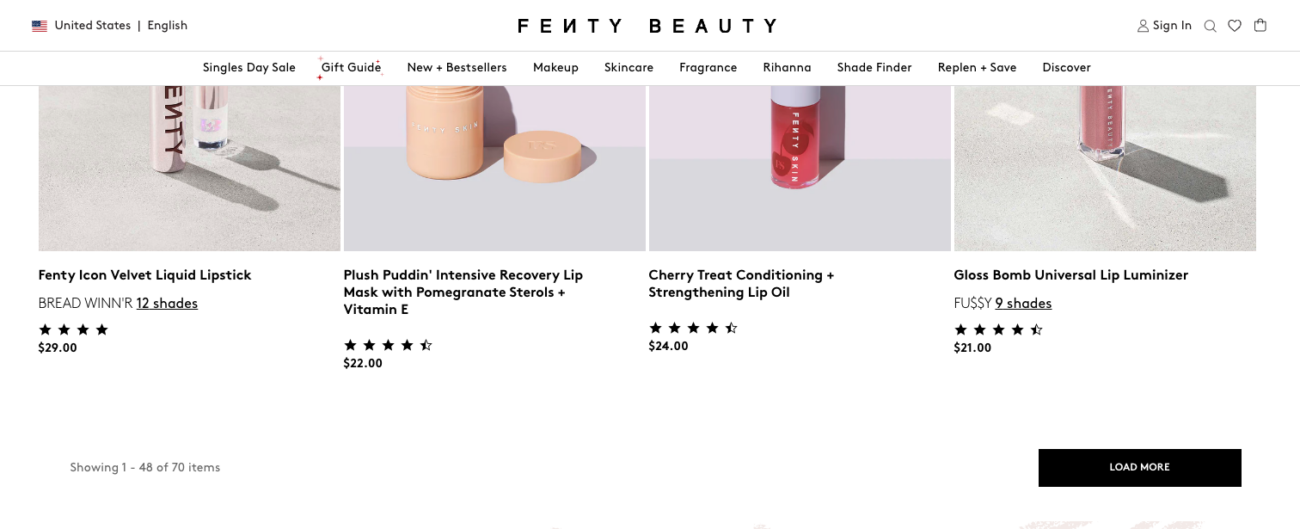
Open the image in a better resolution
Clicking the button will take you to a URL such as https://fentybeauty.com/collections/makeup-lip?page=2,
but that link is nowhere to be found on the parent category.
This means Googlebot will have problems accessing the paginated pages and discovering products that appear below the initial list of items.
Additionally, even if JavaScript is rendered and some links end up being visible – indexing will happen with a delay and take much more time.
If you are interested in that topic, read our case study from 2022:
Rendering Queue: Google Needs 9X More Time To Crawl JS Than HTML
In the end – avoid JS links for critical content and stay with regular hyperlinks.
You are relying on URLs that contain hashes (#)
Fragment identifiers, also known as anchors or hash fragments, are used to navigate to a specific section within a web page.
They allow website admins to link directly to a particular part of a page without loading the entire document. JavaScript and web developers can use fragments to create single-page applications (SPAs) where content dynamically changes without full page reloads based on the fragment identifier in the URL.
URLs containing a hash symbol will not be crawled by Googlebot as a separate page and therefore cannot be validly indexed, unless the content was already present in the source code.
For your content to be found and indexed properly in any framework, it is best practice to use alternative methods of directing search engines to the right page such as creating new unique static URLs without the hash symbol, or using a different separator, such as a question mark (?), often used for parameters.
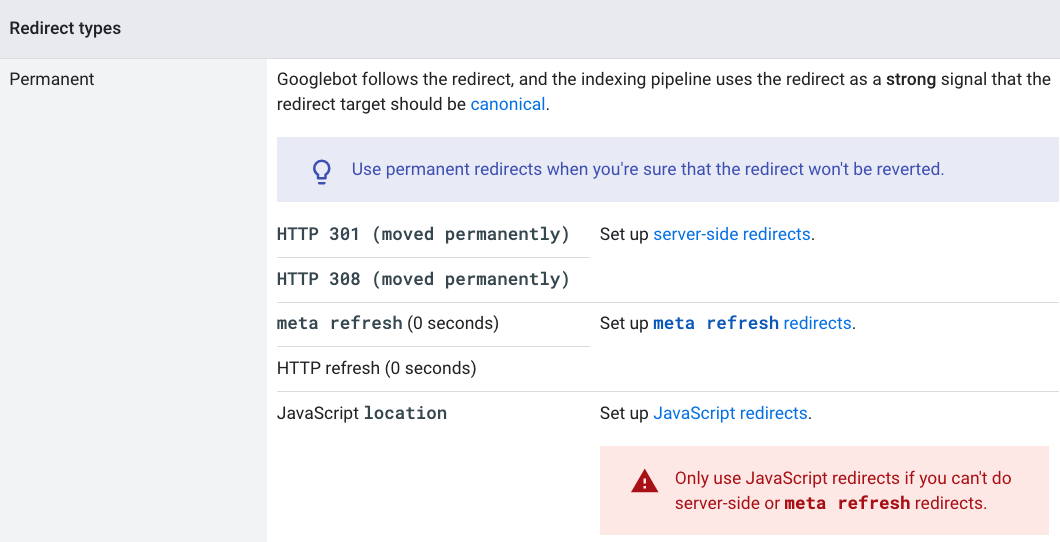
You are using mainly JavaScript redirects
JavaScript redirects can provide a convenient resolution in certain situations, but they may also be detrimental to your online presence if used at scale, as a default implementation.
For permanent user redirection, the go-to solution is to use server-side 301 redirects rather than JS ones. Google can have problems processing JavaScript redirects at scale (because of a low crawl budget or rendering budget). Since Google needs to render each page and execute its JS in order to notice the client-side redirect, JS redirects are less efficient than standard 301s.
Google mentions in their documentation that JS redirects should only be used as a last resort.
Open the image in a better resolution
Also, It can be hard to know if the desired redirect is actually being executed – there is no guarantee that each time Googlebot will execute the JS that triggers the URL change.
For example, if client-side JS redirects are the default solution for a website migration with many URL changes, it will be less efficient and will take more time for Googlebot to process all the redirects.
Additionally, pages that are set to noindex in the initial HTML do not go through rendering, so Google will not see it if they are redirected with JS.
You are expecting Google to scroll down like real users do
As already mentioned in relation to pagination issues, Googlebot cannot click buttons like a human would. Also, Google cannot scroll the page the way regular users do.
Any content requiring such actions to load, will not be indexed.
For example, on infinite pagination pages, Google will not be able to see links to subsequent products (beyond the initial render) as it will not trigger the scroll event.
However, Google is able to render pages with a tall viewport (about 10,000 px), so if additional content is loaded based on the height of the viewport, Google may be able to see “some” of that content.
But you need to be mindful of the 10,000px cut-off point – content loaded lower than this, likely will not be indexed.
What is more, there is no guarantee that Google will use a high viewport at scale – not all pages may get rendered with it, so not all of their content will get indexed.
If implementing lazy-loading, for example, subsequent products on an ecommerce category, make sure that the lazy-loaded items are only deferred in terms of visual rendering (their images are not downloaded upfront but lazy-loaded), but their links and details are present in the initial HTML without the need to execute JS.
Generally speaking, for your website to be indexed properly, all content should load without the need for scrolling or clicking. This allows the entire website to be viewed correctly by both visitors and crawlers alike.
You can use the Inspection Tool in Google Search Console to verify that the rendered HTML contains all the content that you want indexed.
Google nowadays ranks websites based on their mobile versions, which are less likely to be as optimized as their desktop counterparts. As a result of mobile-first indexing, it is necessary to ensure Google can see links on your mobile menu.
Responsive web design is the common answer to that issue.
Best if you use one set of menu links and then style it accordingly to work for all screen resolutions. There is no need to create separate menu instances for multiple resolutions.
This can also cause link redundancies if all menu variants are included in the code at the same time (you will double the number of links from the navigation). If you create separate menus for desktop and mobile, where only one appears in the code depending on the screen resolution, you need to remember that only what is visible on mobile will be indexed (Mobile-First Indexing).
Links present only in the desktop menu will not be taken into account.
Additionally, if your menu is generated by scripts – Google will most likely not crawl it, or at least, not every time. With such an important part of your navigation, this situation is not ideal. If you cannot use solutions like SSR (Server-Side Rendering), please remember to keep your critical links in the unrendered source HTML.
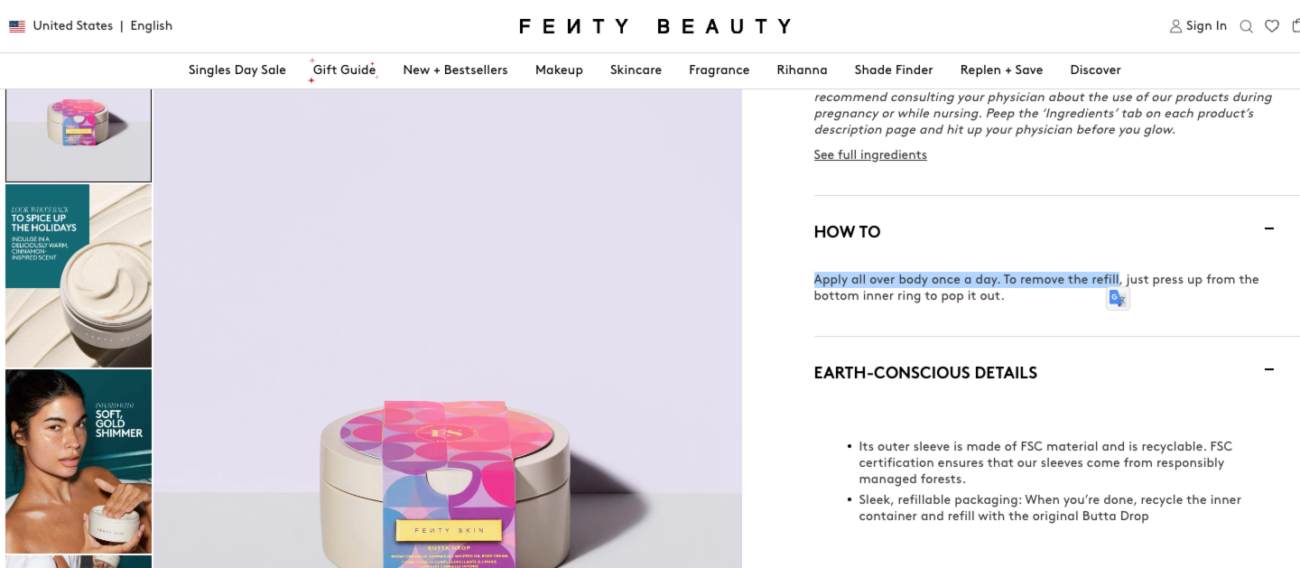
When it comes to JavaScript content loaded dynamically behind tabs, crawlers cannot click them as they do not interact with websites in the same manner as humans. This can prevent Googlebot from accessing content present in tabs and can lead to your website not being indexed correctly.
It is best to avoid hiding content behind tabs or “click here to see more”-type buttons and instead use a combination of CSS and HTML to only temporarily “hide” the content that is already present in the code from the visual render, unless a tab is clicked/tapped.
This way, it is far more likely that content will be indexed.
To verify that Google can index your tabbed content, copy a fragment of text hidden under a tab and search for it using the site: operator with the URL of the webpage:
Open the image in a better resolution
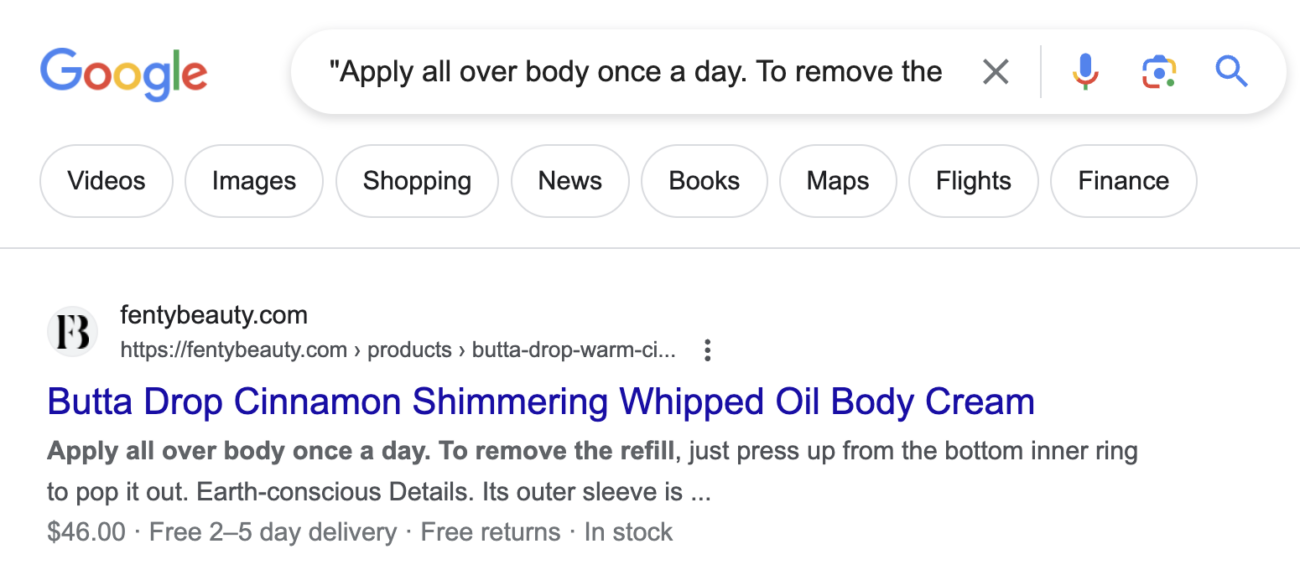
If you see your content in the actual Google Search, you can be certain it got indexed.
You are relying on dynamic rendering
If you take the approach of serving visitors with a fully-featured JS site whilst the server sends a pre-rendered version to Googlebot, that is Dynamic Rendering.
And it can lead to a number of problems.
Firstly, this creates two instances of the website that you need to manage and maintain (each page has its pre-rendered version served to Googlebot based on user-agent recognition), which naturally requires more resources. You are then required to verify that the version served to Google is equal to what real users see, as major content differences can lead to outdated content being indexed, or worse, your site getting penalized for misleading practices.
As of 2023, Google is not recommending dynamic rendering as a valid, long-term solution.
How to detect if your site uses dynamic rendering?*
Open your website as you would normally do, but block JavaScript. Are any important page elements missing? Or perhaps you get a blank page?
Then do the same but switch the user agent to Googlebot – with JS disabled, does the page look the same?
Or perhaps, it looks nearly ready (compared to the blank page seen before)?
If so, your site uses dynamic rendering.
*Note that there are edge cases – if apart from detecting the user agent, you also verify if the request comes from actual Google servers, this will not prove anything. Ask your dev 😉
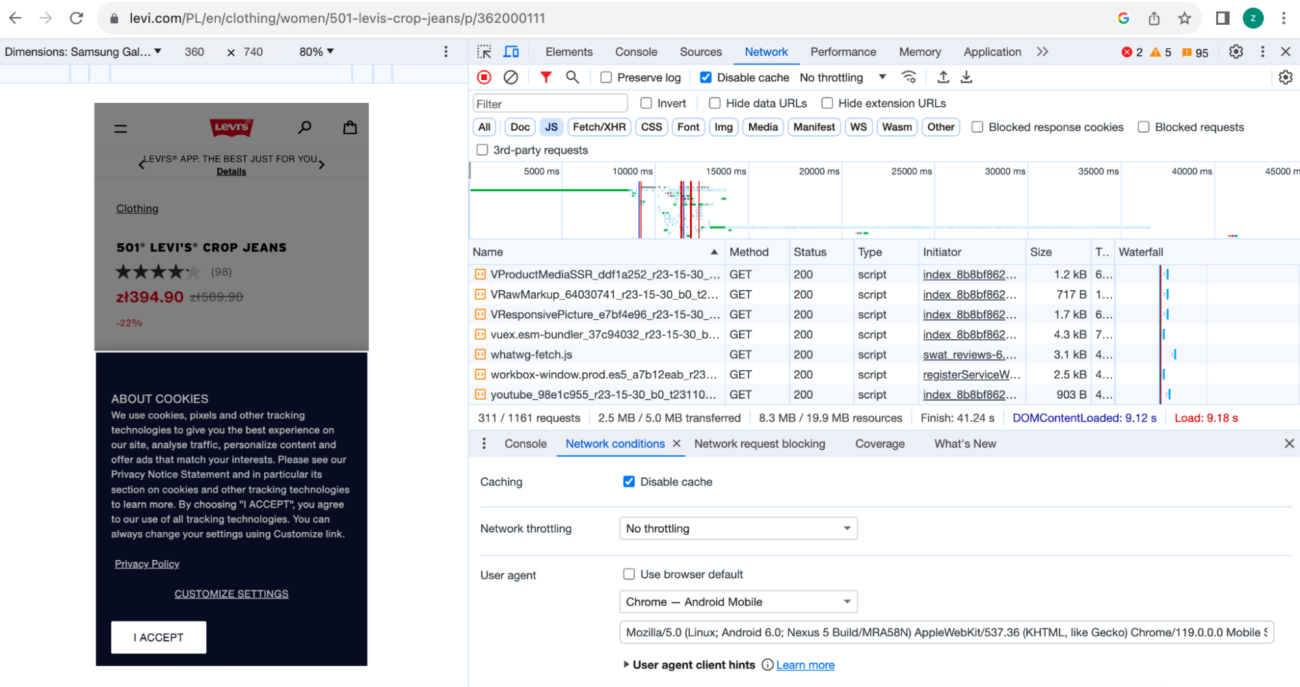
For example, browsing a category page on levi.com: https://www.levi.com/PL/en/clothing/women/501-levis-crop-jeans/p/362000111
With a normal user agent and UA Googlebot shows that the version served to search engine bots does not come with any JavaScript files and looks entirely different from the client-side version.
It is likely the site uses dynamic rendering to serve pre-rendered content to crawlers.
It does not look like it is working correctly though!
Here’s a comparison of content for regular user, and for Googlebot:
Open the image in a better resolution
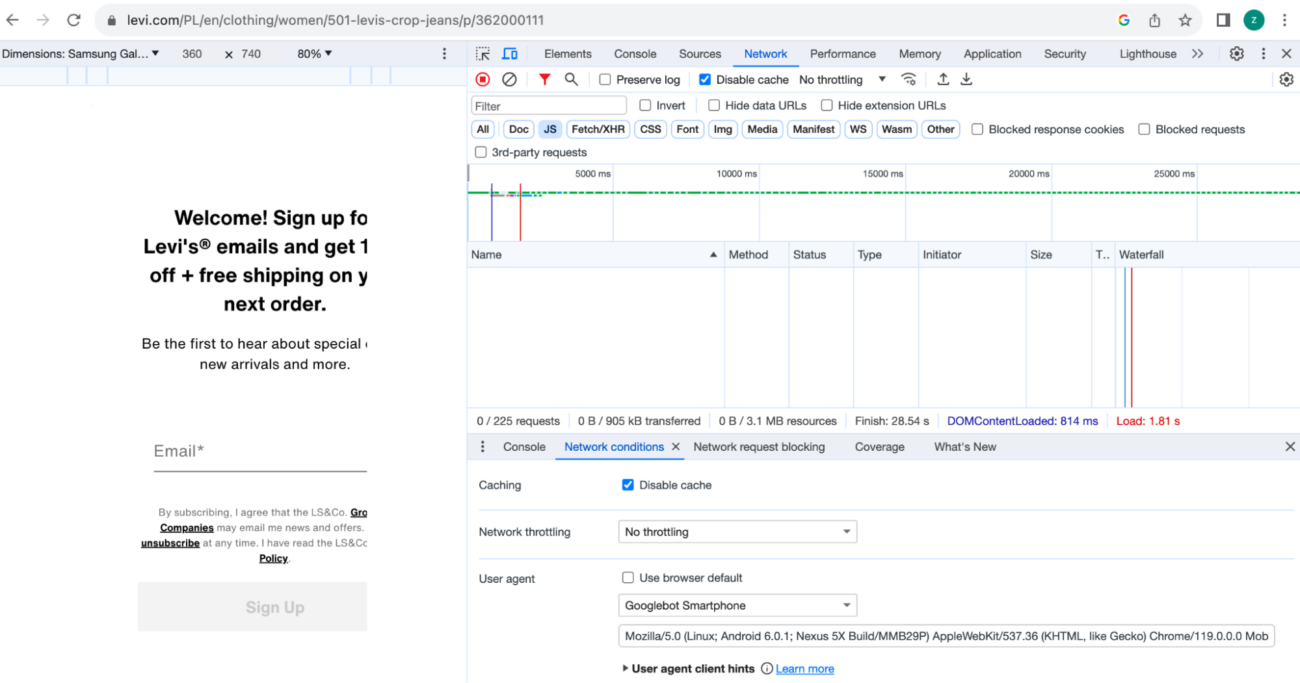
Open the image in a better resolution
Additionally, dynamic rendering can be too intensive for the server/infrastructure causing problems with the availability of the pre-rendered HTML and their response times. If the server-side rendered version is generated ad hoc, this means any backend calculations are performed on the fly, only upon an incoming request from Googlebot.
Depending on the size of the resources and JS payloads, this can take some time, hence resulting in atrocious response times (Googlebot is patient, but will not wait forever!).
If any of the JS chunks are not executed during that calculation, you could be missing parts of the page – therefore, that missing content will not be indexed. If a substantial portion of the content is missing from the prerender, it results in thin-content problems on URLs that Googlebot indexes, and this negatively impacts the quality of the entire site.
The recommended long-term solution is to serve the same server-side rendered version of your pages to both crawlers and users. In other words, remove detecting if the incoming request comes from user agent Googlebot to serve it dedicated content – just serve rendered content to everyone.
Your error pages are indexed (soft 404 errors)
When pages return a 200 status code instead of the expected 404 one, such pages may end up being indexed, creating index bloat. In some cases, this is related to JavaScript changing the site content.
This can affect the performance of your website in search results, so it is critical to verify that 404 error codes are returned to Googlebot as expected. This becomes even trickier if your site uses dynamic rendering.
To detect that, you can crawl your website with the software of your choice and search for pages that return 200 HTTP status codes, but do not serve any unique value. For example, have the same duplicate title informing that the page does not exist. If you suspect the issue is related to JavaScript, remember to run a JS crawl, not a regular one.
You can also use Google Search Console to identify URLs that are returning 200 HTTP status codes instead of 404 errors. They are usually marked as “Soft 404” in the Page Indexing report.
Then, it is just a matter of changing them to “regular” 404s, with accurate HTTP status code.
You are using large JS (and CSS) files that slow down the page’s performance
Besides the issues related to indexing, JavaScript can also have an impact on your website’s speed. This affects SEO performance and leads to your website ranking lower in search results.
As crawlers can measure the loading time of websites, it is often useful to reduce the size of large files (both JS and CSS) so that your website can be loaded quickly.
To address this issue, you can use a number of tactics such as:
- Reducing the amount of unused JavaScript/CSS.
- Minifying and compressing your JS/CSS files.
- Making sure JS/CSS is not render-blocking.
- Deferring JS that is not needed for the initial page render (for example, JS that handles user-interactions).
- Reducing the use of third-party libraries.
These can all contribute to reducing the size of your files so that they can be loaded quickly, providing an overall positive experience for both visitors and search engine crawlers.
Core Web Vitals (CWVs) are a set of user-centered metrics introduced by Google to assess the loading performance, interactivity, and visual stability of web pages.
The quickest way to access the CWVs scores for any website is to use PageSpeed Insights.
Input your URL into the PSI tool and provided that the data sample is large enough, the tool will display page speed metrics and how your page scores in them based on real-life data from the actual users of your site.
Click on each metric name to see definitions and background on how each metric is calculated.
Here is an example of a PSI result, based on fentybeauty.com page:
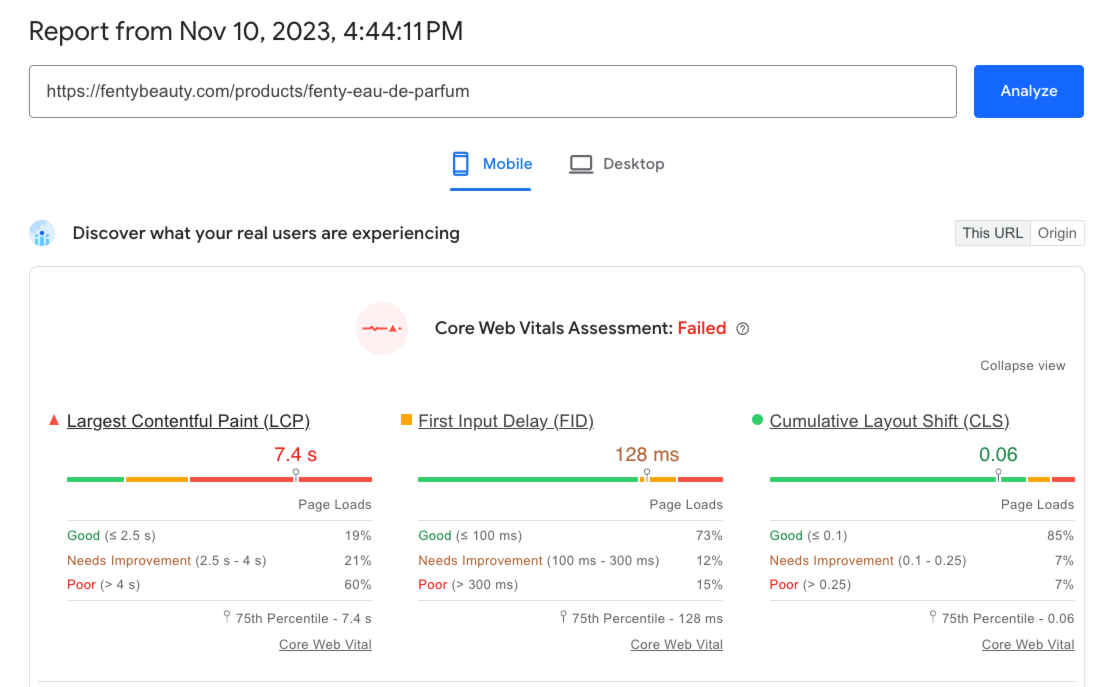
Open the image in a better resolution
The tool not only gives you real user metrics, but also a set of actionable recommendations to share with your development team.
Wrapping up – JavaScript errors do hurt SEO
It is clear that JS can have a significant impact on search engine optimization. Whilst JavaScript goes a long way towards delivering an improved user experience, it can also create issues with indexing and even result in your website being ranked lower in search results.
To minimize the effect of these issues, it is worth reviewing your website’s performance and addressing any of the abovementioned JavaScript issues that are present.
If you cannot cover these issues on your own, working with an experienced SEO specializing in JS will help. At Onely, we are working to get your website indexed even with JS dependencies and provide an overall positive experience for both visitors and search engine crawlers.



